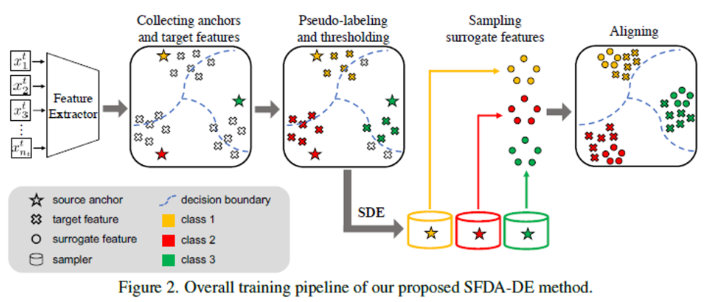
0. Abstract 선생님과 학생 사이의 중간 스타일을 전달하여 보조 특징을 생성하고, 그런 다음 학생과 보조 사이의 출력 불일치를 최소화함으로써 모델을 훈련시킵니다. 훈련 중에 보조들은 두 도메인 간의 불일치를 서서히 줄이므로 학생이 선생님으로부터 쉽게 학습할 수 있도록 1. Introduction 도메인 적응의 목표는 원래 도메인(소스)에서 사용 가능한 레이블 데이터를 사용하여 학습자를 새로운 도메인(타겟)에 적응시키는 것 도메인 내 불일치와 도메인 간 불일치 고려 AF가 굳이 필요한 이유: 혼합 스타일 특징으로 훈련하는 것은 도메인 불일치를 줄이는 데 도움이 됩니다 [12, 45]. 이 사실에서 영감을 받아 보조 특징은 선생님과 학생 사이의 중간 스타일을 전송하여 생성됩니다. 그런 다음 모델은 학..