[논문 리뷰] Tent: Fully Test-time Adaptation by Entropy Minimization (ICLR 2021)
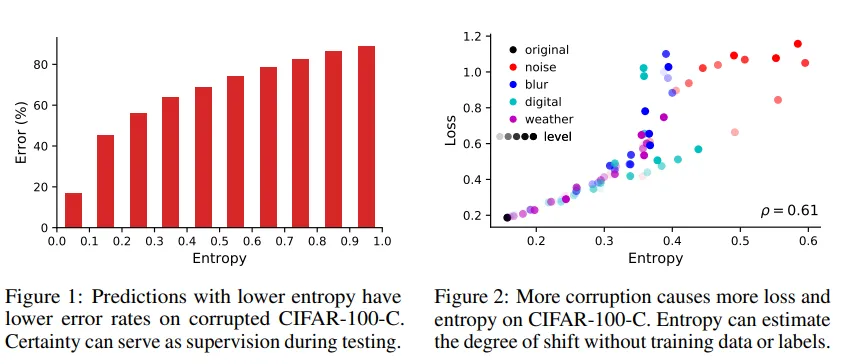
방법론의 목적문제정의현실 문제: 딥러닝 모델은 훈련 데이터와 유사한 분포에서는 높은 정확도를 보이지만, 도메인 시프트가 발생하면 성능이 크게 하락. 예) 카메라 노이즈, 날씨 변화, 센서 고장 등.기존 한계: 일반적인 도메인 적응 방법은 소스 도메인 데이터를 다시 사용하거나, 테스트 환경을 미리 아는 경우에만 유효함.현실적 제약: 테스트 시점에는 소스 데이터 접근이 불가능하거나 비용이 많이 드는 경우가 많음 (예: 개인정보보호, 제한된 리소스, 지연 시간 이슈 등)목표Fully Test-Time Adaptation (FTTA): 사전 훈련된 모델의 구조와 가중치는 유지하며, 테스트 배치에서만 적응 수행: 소스 데이터 없이, 테스트 시점의 입력 데이터만으로 모델이 환경 변화에 적응하도록 만드는 방법론 제안..