Abstract
- Mased auto encoders(MAE)가 컴퓨터 비전 분야에서 scalable self-supervised learners 임을 증명
- 아이디어 : 입력 이미지의 패치를 랜덤하게 마스킹한 후 missing pixels를 복원하도록 학습
- 인코더-디코더 구조는 비대칭 구조.
- 인코더: 마스킹 되지 않은 부분만 처리
- 디코더: 인코더보다 훨 가볍게 설정되고 마스킹된 부분과 되지 않은 부분 모두 처리
- 입력 이미지에 대한 최적 마스킹 비율 : 75%
- 학습 속도&정확도 높일 수 있었음
- 최종적으로 transfer learning 성능도 검증
Intro
딥러닝이 핫해지고 하드웨어들이 발전하면서 거대한 모델들이 엄청나게 많은 데이터를 overfit하게 학습하게 되었고 수 백만의 labled 이미지를 필요로 하게 되었다.
NL에서는 autoregressive 언어 모델인 GPT와 masked autoencoding 모델인 BERT가 성공했는데,
매우 simple한 아이디어: 데이터의 일부를 지우고, 지운 내용 예측하도록 모델 학습
- Masked autoencoder
- Denoising autoencoder의 일부
- NLP에서 성공한다음 cv에서도 성공적으로 안착하려고 함
- NLP와 CV 차이점
- (1) Architecture가 다르다
- 컴퓨터 비전에서는 일반적으로 CNN을 사용하는데 이는 NLP와 다르게 mask token 혹은 positional embedding과 같은 indicators가 존재하지 않는다.
- ⇒ 하지만 ViT의 등장으로 어느 정도 해결될 수 있었다.
- (2) Information density가 다르다
- NLP: highly semantic & information-dense
- CV: sptial redundancy (이웃 패치로부터 missing 패치가 충분히 회복될 수 있음)
- (3) Autoencoder의 Decoder가 수행하는 바가 다르다
- NLP: missing words를 예측하는 역할. 풍부한 semantic 정보를 포함하여야 함
- CV: Pixels를 재구축하는 역할. 상대적으로 덜 semantic함
- (1) Architecture가 다르다
위와 같은 차이점들을 고려하여 본 연구는 MAE의 간단하고, 효과적이고, Scalable한 형태로 visual 표현학습을 할 수 있도록 제안한다.
- 모델 구조
- 모델의 구조는 아래와 같이 인코더와 디코더가 비대칭적인 형태를 띈다.
- 디코더는 훨씬 가벼운 형태로 마스크 토큰과 함께 latent representation을 사용하여 재구축하게 된다.

- Contribution
- 마스크 토큰을 디코더에서 활용할지라도 상당히 작은 구조를 띄고 있기 때문에 계산 측면에서 많은 감소가 존재한다.
- 높은 마스킹 비율은 인코더가 작은 부분만 처리할 수 있게 하면서 정확도 또한 최적화할 수 있다.
- 전반적인 transfer learning 시간을 줄이고, 메모리 소비를 줄여 MAE를 거대 모델에 쉽게 스케일업 할 수 있게 한다.
Related work
- Masked language modeling
NLP에서의 성공적인 사전학습 모델인 BERT와 GPT가 대표적이다.
입력 시퀀스의 일부를 지우고, 지워진 부분을 재복원할 수 있도록 학습하는 전략이다.
- Autoencoding
오토인코더는 인코더에서 입력 데이터를 잠재 표현에 매핑하고, 디코더에서 재복원하는 모델이다.
DAE는 입력 신호를 망가뜨리고, 재복원 시에 온전한 신호로 복원하는 방법이다.
픽셀을 마스킹하는 방법이나 색상 채널을 제거하는 방법이 DAE의 일종이라고 볼 수 있다.
- Masked image encoding
마스킹에 의해 망가뜨려진 이미지로부터 표현을 추출하는 방법이다.
DAE에서의 노이즈의 일부로 마스킹을 보는 것이다.
초기 연구로는 iGPT, BEiT 등이 있다.
- Self-supervised learning
사전학습을 위해 여러 pretext task 집중하는 방법이다.
최근에는 대조학습이 제일 유명하긴 한데 이는 data augmentation에 너무 의존한다는 단점이 있다.
오토인코더를 활용하는 것은 개념적으로 다른 방향을 추구하는 것이고, 제시하고자 하는 행동 또한 다르다.
Approach

모델의 구조는 앞서 계속 언급했듯, 오토인코더의 형태를 띈다.
인코더는 입력 데이터를 잠재 표현으로 매핑하고, 디코더는 잠재 표현으로부터 입력 데이터를 복원한다.
하지만 일반적인 오토인코더와는 다르게, MAE의 인코더는 마스킹이 되지 않은 부분만을 입력으로 사용하고, 디코더는 마스크 토큰과 잠재 표현 모두를 사용해서 입력 신호를 복원한다.
그리고 디코더는 인코더보다 훨씬 가벼운 형태를 띈다.
- Masking
- ViT를 따르기 때문에, 이미지를 안 겹치는 패치로 자른다.마스킹 비율을 높게 가져가서 중복을 상당히 많이 제거한다. 그래서 visible 이웃 패치로부터의 외삽으로 주변이 쉽게 예측되지 않도록 한다.
- 그 후 비복원추출로 랜덤하게 마스킹할 패치를 선택한다. 이 때 랜덤하게 선택할 확률은 Uniform 분포를 따르도록 한다. Center bias를 방지하기 위해서다.
- MAE encoder
- 마스킹되지 않은 25% 정도의 visible 패치만 사용하기 때문에 아무리 큰 ViT 인코더를 써도 속도가 상당히 빠르다.
- MAE decoder
- 디코더는 visible 패치와 mask token 모두를 입력으로 받는다.디코더는 이미지 복원 작업을 수행하는 사전학습 시에만 사용되기 때문에, Flexible하게 구성하면 된다.실제 논문에서는 토큰 별로 인코더보다 디코더에서 1/10 속도로 처리 가능하도록 했다.
- 인코더 구성과 독립적으로 만들면 되기 때문에 비대칭적으로 가볍고, 좁은 네트워크로 구성해도 된다.
- 그리고 꼭 positional embedding을 추가해줘야 하는데, 없으면 mask token이 아무 정보를 못 갖게 된다.
- Reconstruction target
- MAE는 masked 패치의 픽셀들을 예측함으로써 입력 데이터를 복원한다.손실 함수는 MSE를 사용하며, 오직 masked 패치에서만 손실 함수가 계산된다.
- 추가로 Reconstruction target을 정규화된 픽셀 값으로 사용하기도 하는데, 그렇게 한다면 표현 품질이 향상된다.
- 디코더의 출력은 픽셀 벡터들이다. 출력한 후에는 reshape을 통해 원본 이미지 형태로 변환된다.
- Simple implementation
- 샘플링 시에 어떠한 sparse operation이 필요없기 때문에 상당히 효율적이다.
- 그저 positional embedding으로 각 패치별로 순서 부여하고, 랜덤하게 셔플하고, 뒤에서부터 마스킹 비율에 맞게 제거하는게 끝이다. 그리고 디코더에서 다시 복원할 때는 원래의 postional embedding에 맞게 세우면 된다.
ImageNet Experiments
사전학습은 ImageNet-1K 데이터셋을 사용했다.
Baseline 모델은 ViT-Large를 사용했는데, 이는 굉장히 크기 때문에 오버피팅 문제가 존재한다.
하지만 제안하는 MAE를 사용하면 지도학습 방식으로 사전학습 시키는 것보다 오버피팅 문제가 적기에 훨씬 성능이 좋다.

scratch, our impl은 규제 term을 하나 추가해서 성능을 높인 것이다.

Ablation study의 시작은 마스킹 비율에 관한 실험으로, 75%가 가장 좋은 성능을 얻음을 확인할 수 있다.

실제 이미지 예시를 살펴봐도 75%를 마스킹했을 시에는 상당히 괜찮게 복원하지만, 이보다 더 많은 비율을 마스킹하면 복원이 힘든 것을 볼 수 있다.

위 표들은 Ablation study의 각 결과들이다. Decoder depth, width를 보면 그렇게 깊게 혹은 넓게 쌓을 필요가 없음을 알 수 있다.
인코더에서는 masked token을 사용하지 않을 때가 더 좋은 성능에 더 빠른 연산 속도를 보였다.
Reconstruction target을 여러 시나리오로 구성 가능한데, 정규화한 픽셀 값을 복원할 때가 성능이 가장 좋았다.
Data augmentation에 있어서는 꽤나 강건한 것을 알 수 있다.
Mask sampling은 랜덤하게 할 때가 가장 좋았다.

오히려 랜덤하게가 아니라 다른 규칙을 기준으로 하면 많은 부분을 마스킹할 수 없게 되고, 많은 부분을 마스킹하면 왜곡된 결과가 나오는 것을 알 수 있다.
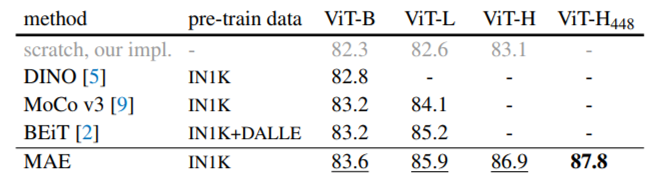
대조학습 모델 MoCo나 지도학습 기반 BEiT 같은 모델을 활용해서 사전학습하는 것보다 MAE가 더 뛰어났다
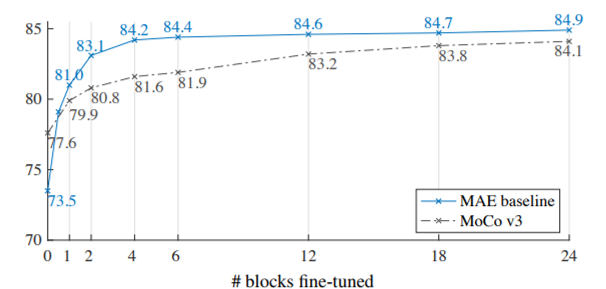
Fine-tuning 할 수록 성능이 더 좋아지긴 하는데, 큰 차이가 없기 때문에 어느 정도는 Freeze 시키고 뒤 쪽만 Fine-tuning하는 것이 더욱 좋은 전략일 것이다.
Transfer Learning Experiments
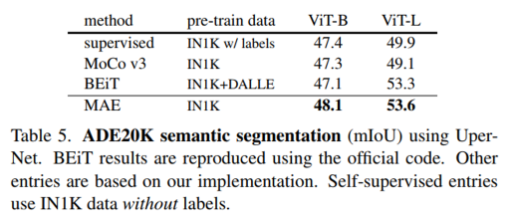
Semantic segmentation Task에서도 MAE로 사전학습 시켰을 때 mIoU가 가장 좋았다.
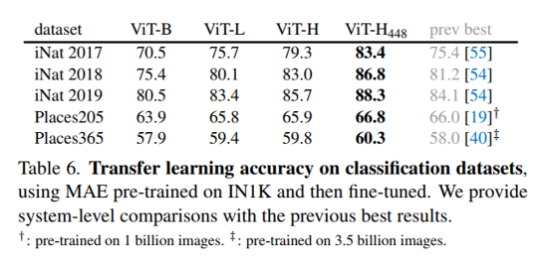
다른 이미지 데이터셋에 대한 분류 실험에서도 MAE가 제일 좋았다.

Reconstruciton target을 픽셀로 할 것이냐, Token으로 할 것이냐 고민할 수 있는데,
대부분의 전이학습 상황에서 픽셀로 할 때 성능이 더 우수했다.
Discussion and Conclusion
NLP에서 성공적이었던 자기지도학습 방법 BERT를 성공적으로 컴퓨터 비전에 접목시켰다고 할 수 있다.
그치만 논하고자 하는 것은 NLP에서는 결국 Semantic한 단어를 가리게 되는데, 비전에서의 패치가 Semantic하냐는 것이다. 그렇다면 픽셀도 Semantic 한가? 그래서 사실 Semantic 한 것을 가리려면 객체(Object)를 가리는 것이 더욱 논리적일 것이다.
하지만 그러기에는 어려우니까 저자는 높은 마스킹 비율을 사용해서 대부분을 가려버리면 비슷한 효과가 있지 않을까 주장하는 것이다.