0. Abstract
- 기존 NN에서 accuracy 향상 방법
- 깊거나 더 확장된 네트워크
- 이 논문에서 NN에서 accuracy 향상 방법 : Self-distillation
- 기존 Knowledge distillation
- student network를 pretrain된 teacher모델의 softmax layer output에 근사하도록 함
- self distillation
- 자기 자신의 네트워크에서 정보 증류
- 방법
-
- 여러 section으로 나눔
- 더 깊은 네트워크의 지식을 낮은 곳으로 squeeze해줌
-
- 기존 Knowledge distillation
1. Introduction
[1] 예측 정확도 향상 & 반응 시간/컴퓨터 자원 감소 필요함
- 기존에 시도된 모델들
- ResNet 150, ResNet1000 : 성능 조금 향상 & 엄청 거대한 자원량
- (모델 경량화) lightweight network design, pruning, quantization, Knowledge Distillation : 자원량 줄이려는 노력들
[2] Knowledge Distillation 소개 & 문제점
- 개념
- 교사 → 학생의 knowledge transfer에서 영감 받음
- compact한 학생 모델이 over-parameterized한 교사 모델에 근사하도록 !
- 결과
- 학생 모델이 중요한 성능 향상 이뤄냄 (가끔은 교사보다 좋을때도 있긴함)
- 결과 해석
- over-parametrized한 교사 모델이 compact한 학생 모델이 되면서, 자원 감소 & 빠른 학습 가능
- 문제점
- knowledge transfer에 저효율= 교사모델보다 더 뛰어난 성능을 낼 수 없음
- = 학생 모델이 드물게 교사모델로부터 모든 정보를 가져옴
- 적절한 교사모델 디자인하고 학습하는 방법
- = 현존하는 distillation framework는 교사모델의 best 아키텍처 찾는데에 많은 노력,시간 필요
[3] Self-distillation 간략 소개

- 그림1 해석
- Traditional model distillation
- 2 step( 거대 교사 모델 학습 → pretrain된 교사 모델로 학생모델 학습)
- self distillation
- 1 step
- Traditional model distillation
[4] self-distillation: Contribution
- response time없이 성능 향상 가능 !
- 다른 depth의 단일 neural network에서 실행가능하도록 함.
- & 자원-제한적인 edge devices에, 정확도-효율성 trade-off 달성 가능
- CNN의 5종류 실험에 대해서 일반화된 결과 도출 가능
2. Related work
knowledge distillation
[1] 학생 모델이 교사 모델의 정보를 더 많이 수용하기 위한 시도들
- FitNet
- hint learning : 교사와 학생 모델의 feature map간 거리 감소
- Attention mechanism
- attention의 feature들 정렬시키기
- Generative adversarial problem
[2] 다른 도메인에서의 Knowledge Distillation
- 일반화 성능 좋게 하기위한 적용
- distilated된 학생 모델이 교사 모델에 흡수됨
- data augmentation를 위한 적용
- 더 높은 entropy를 위해 label값의 수를 늘림
- adversarial 공격에 대한 방어를 위한 적용
- 서로 다른 modal끼리의 정보 이동을 위한 적용
Adaptive Computation
: 과자원량 없애기 위해 몇몇 computation 과정 건너뜀
[1] Neural network에서 몇몇 layer skip
- 학습 시 랜덤 layer-wise dropout 하기
- 추가적인 controller를 통해 inference도 해서 랜덤 layer-wise dropout 하기
- 평균 execution depth 감소시켜서 early-exiting prediction branches로
[2] Neural network에서 몇몇 channel skip
- switchable batch norm: inference에서 동적으로 채널 조정
[3] 현재 input 이미지의 덜 중요한 pixel들 skip
- input data의 중요한 detail에 집중 가능
- 강화학습과 딥러닝에서,, CNN 들어가기 전에 input 이미지의 중요 픽셀 찾기 가능
Deep Supervision
[1] 개념
- 정의: 고도의 변별력있는 feature들에서 inference때 성능 향상하도록 학습함
- gradient vanishing해결 위한 방법
- 추가적인 supervision이 직접적으로 hidden layer에 train되도록해서 성능 향상 하도록
- image classification, object detection , image segmentation에서 적용 됨
[2] self-distillation에서의 적용
- 두 가지의 유사성
- self-distillation에 적용된 multi-classifier architecture = deeply supervised net
- 두 가지의 차이점
- self-distillation : 단일 label 대신 shallow classifier로 학습됨
- → 더 성능 향상되도록 가능
3. Self-Distillation
[1] 구조 & 학습 방법
- 구조
- 몇개의 shallow section들로 나뉨
- classifier = bottleneck + fc layer (학습 시에만, inference때는 없앰)
- bottleneck : shallow classifier에서 영향력 완화 & hint features로부터 L2 loss 더함
- 학습 시,,
- 모든 shallow sections에 해당하는 classifier들은(bottleneck, fclayer) distillation통해 학생 모델로 학습됨
[2] 학생 모델 성능 높이기 위한 3가지 loss function
- 1) cross entropy loss from labels
- deepest classifier(교사)와 shallow classifier(학생) 모두에 영향 줌
- trainset의 label + 각 classifier의 softmax layer의 output으로 계산된 것
- 2) KL divergence loss from distillation
- 교사 모델의 KL divergence loss로부터 계산됨
- KL divergence는 학생과 교사 간의 softmax output 사용해서 계산되고
- → 각각의 shallow classifier의 softmax layer로 introduce 됨.
- 교사 모델의 KL divergence loss로부터 계산됨
- 3) L2 loss from hints
- deep classifier의 feature map과 각각의 shallow classifier 사이의 L2 loss 계산한 것
- L2 loss → 각 shallow layer의 feature map이 deep classifier의 feature map과 유사해지도록
3.1. Formulation
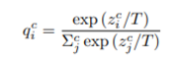
- N: sample 개수
- M: class 개수 (개, 고양이, 다람쥐)
- c: classifier 개수(1번 분류기, 2번 분류기, 3번 분류기)
- z: fc layer 이후 output
- T: 확률 분포 정규화 temperature (일반적으로 1로 세팅; 클수록 분포 부드러워짐)
- q: c번째 classifier에서 class 확률
3.2. Training Methods


4. Experiments
- self distillation 평가 지표들
- 5개의 CNN network
- ResNet, WideResNet, PyramidResNet, ResNeXt, VGG
- 2개의 dataset으로
- CIFAR100, ImageNet
- learning rate decay, l2 regularizer, simple data argumentation 학습 시 사용
- 5개의 CNN network
4.1. Benchmark Datasets
- CIFAR100
- 32x32 RGB image
- 100개 class + 50K train images + 10K test images
- ImageNet
- 256x256 RGB image(resize한것)
- 1000개 class(wordNet으로부터 가져온것) + 각 class는 1000개의 이미지로부터 만들어짐
- accuracy는 validation set으로부터 나온 숫자
4.2. Compared with Standard Training
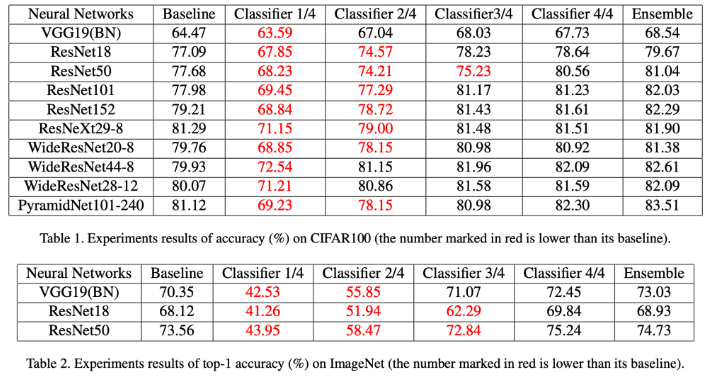
Ensemble: 각 분류기의 softmax layer의 가중치가 부여된 출력을 단순히 추가
- 결과 해석
- 1) 모든 신경망이 self-distillation으로 성능향상 이루어냄
- CIFAR100은 평균 2.65%, imageNet은 평균 2.02% 성능 향상
- 2) (CIFAR100에서) 신경망이 더 깊을수록 성능향상 크게 이루어냄
- ex. (baseline과 비교했을때) ResNet18에서는 2.58% 향상, ResNet101에서는 4.05% 향상
- 3) CIFAR100에서 단순 앙상블이 효과적으로 작동, ImageNet에서는 덜 효과적이거나 부정적 영향
- ImageNet에서 얕은 분류기의 정확도가 CIFAR100에서보다 더 크게 떨어지기 때문
- 4) 분류기의 깊이: ImageNet에서 더 중요한 역할
- 1) 모든 신경망이 self-distillation으로 성능향상 이루어냄
4.3. Compared with Distillation

- Table 3: CIFAR100으로 5가지 전통 distillation과 self-distillation 비교
- 전제 조건: 학생 모델들이 동일 계산 및 저장량 가질 때, 각 방법의 정확도 향상에 초점
- 결과 해석
- 1) 모든 distillation 방법이 직접 훈련된 학생 네트워크(baseline)보다 성능 우수
- 2) self-distillation은 추가적인 교사모델이 없음에도, 다른 방법들보다 성능 우수 & 4.6배 빠른 학습시간
- 전통 distillation: over parametric 교사모델 설계&학습해야 함
- 최적의 깊이와 아키텍처 찾기 위해 많은 실험 필요
- over parametric 교사모델 학습하는데에 긴 소요시간 필요
- 전통 distillation: over parametric 교사모델 설계&학습해야 함
4.4. Compared with Deeply Supervised Net
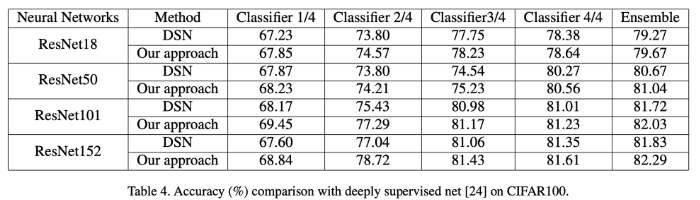
- Table 4: CIFAR100으로 deeply supervised net(DSN)과 self-distillation 비교
- DSN과 self-distillation 차이점: self-distillation은 label대신 가장 깊은 분류기의 distillation에서 얕은 분류기 학습
- 결과 해석
- 1) self-distillation이 모든 분류기에서 DSN보다 좋은 성능
- 2) 얕은 분류기는 self-distillation일때 더 좋은 성능 (더 많은 차별화된 특성 얻기 가능+깊은 분류기의 성능 강화 가능)
- 이유1: self-distillation은 얕은 분류기와 깊은 분류기 사이의 충돌 피하기 위해, 분류기 특정 기능을 감지하는 추가 병목 계층 도입
- 이유2: 성능 향상 위해 얕은 분류기를 훈련시키는데 label대신 distillation 방법 사용함.
4.5. Scalable Depth for Adapting Inference
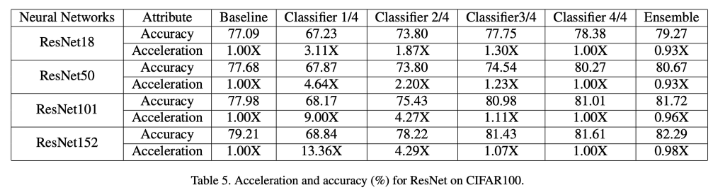
- 최근 추세: 확장 가능한 네트워크 설계 → 컨볼루션 신경망의 속도를 높이기 → 인기 있는 해결책 !
- ex. 응답 시간>정확도 시나리오 일때 → 일부 layer나 채널포기하고 실행 시간 가속화
- sharing backbone network사용 시, 자원 제한적인 edge device에서 inference시 적응형 정확도-가속화 trade-off 가능
- = 실제 세계에서 변화하는 정확도 요구에 따라 각기 다른 깊이의 분류기로 적용 가능
- Table5: CIFAR100으로 ResNet 깊이별 학습속도와 정확도 비교
- 결과 해석
- 1) 4개의 신경망 중, 3개가 3/4 classifier일때 baseline 초과하여 평균 1.2X의 가속 비율 달성
- 2/4 classifier일때 평균 3.16X의 가속 비율& baseline과 비교했을때 3.3%의 accuracy loss
- 2) 가장 깊은 3개의 classifier 앙상블은 평균보다 0.67% accuracy개선, 평균 0.05% 향상된 속도
- 다른 classifier들이 하나의 백본 네트워크를 공유하기 때문 (아래에 이유 적음)
- 1) 4개의 신경망 중, 3개가 3/4 classifier일때 baseline 초과하여 평균 1.2X의 가속 비율 달성
- 결과 해석
5. Discussion and Future Works
self-distillation 성능개선을 위한 평탄한 최소값(flat minima), 소실하는 기울기(vanishing gradients), 그리고 차별화된 특징(discriminating features)에 대해 논의
- Self distillation can help models converge to flat minima which features in generalization inherently (self-distillation은 모델이 일반화 특성을 내재적으로 가지는 flat minima로 수렴하도록함)
- 일반적인 상식
- AlexNet같은 얕은 신경망 → trainset loss=0 가능, but testset에서는 깊은 신경망(ResNet)보다 한참 성능 뒤쳐짐
- 일반적인 상식
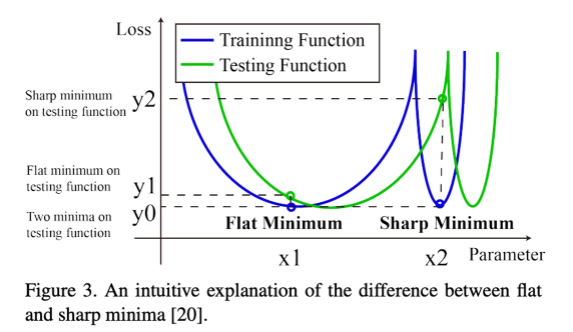
- Fig3 해석 : train과 testset의 손실 곡선 (이 논문에서 직접 실험한 것X)
- x축: 모델의 매개변수를 한 차원으로
- y축: 손실 함수의 값
- 1) 두 최소값(x1은 평탄한 최소값, x2는 날카로운 최소값) 모두 훈련 세트에서 매우 작은 손실(y0)을 달성 가능
- 2) train과 test를 비교할때, sharp minima일때 bias가 flat minima일때 bias보다 큼
- 훈련 세트와 테스트 세트는 독립적이고 동일하게 분포되어 있지않기때문
- (= y2 - y0가 y1 - y0보다 훨씬 큼)
- self-distillation에서 flat minima에 수렴가능성을 보여주기 위한 증명
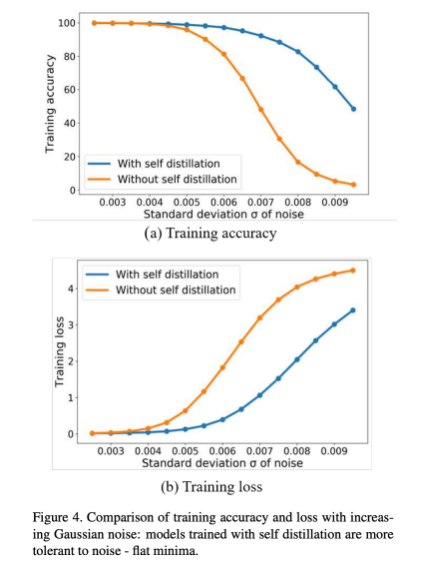
- 결과 해석
- self-distillation으로 model train할때 더 flat한 경향성
- -> 이유(내 생각): soft label때문에 일반화를 더 잘해서
2. Self distillation prevents models from vanishing gradient problem
: deep neural network에서 gradient vanishing 안일어나도록 함(각기 다른 깊이에서 supervision은 주입해줬기 때문에 가능)
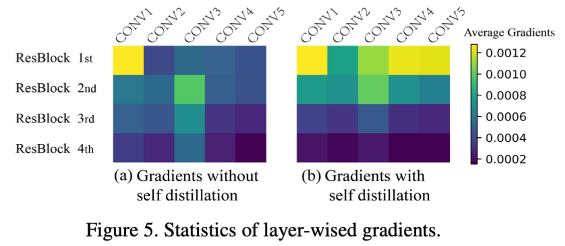
- 실험 세팅
- two-18 layer ResNet
- 하나는 self distillation 포함, 하나는 불포함
- 결과 해석 (gradient 양에 대한 히트맵)
- 1) 1st와 2nd ResBlock에서 (a)보다 (b)일때 더 많은 gradient 가진걸 보임(=gradient vanishing이 덜 일어난 것)-> 이유 (내 생각): bottleneck layer때문에 가능한듯
3. More discriminating features are extracted with deeper classifiers in self distillation
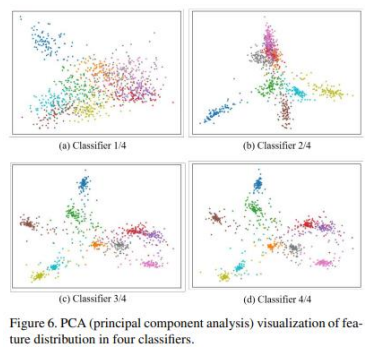
- 결과해석
- Deep할수록 각 feature끼리 cluster가 더 잘됨
- Shallow classifier에서 거리변화가 더 심함
코드
https://colab.research.google.com/drive/1eSrVMGc6X9JM39aGK6VpH5H0Zfilb_sF?usp=sharing
skd_train.ipynb
Colaboratory notebook
colab.research.google.com
(https://github.com/luanyunteng/pytorch-be-your-own-teacher 깃허브 코드 참고함)
Comment
1. flat/sharp/local/global minma 차이?
2. Table5의 숫자들이 self-distillation이 아닌 DSN에 대한 숫자들임. 왜 DSN으로 채워진건지..? 이 논문에서 학습속도에 대한걸 강조하고 싶으면 self-distillation에 대한 속도를 측정해서 숫자를 넣어야하지 않나?
3. Table3의 our approach에서 앙상블한 결과가 아닌, 4번째 classifier의 값들로 비교한 이유? (다른 모델들이 앙상블하는 애들이 아니여서?)