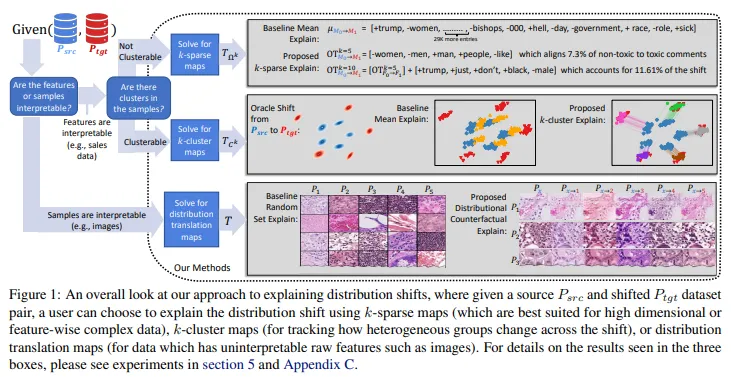
방법론의 목적 기존 연구 대부분은 변화가 발생했는지 여부를 탐지하는 데에만 초점을 맞추고 있으며, 탐지된 변화를 인간이 적절히 이해하고 처리할 수 있다고 가정함.이러한 수작업 완화 작업을 지원하기 위해, 원본 분포에서 변환된 분포로 이동을 설명할 수 있도록 함.class distribution shift에 대한 대응 (=ex. 이상일때 shift발생하는데, 정상일때와 뭐가 다르길래 발생하는지 알려줌) 주목해야할 점 Interpretable Transportation Map을 활용하여 분포 변화를 설명하는 방법론 Transportation Map 소스와 타겟 두 분포 사이의 관계를 설명하기 위해, 데이터를 한 분포에서 다른 분포로 변환하는 map ex. 변환 맵이 간단한 수학 공식이나..