0. Abstract
- 분류 모델에서 확률 예측이 실제 correctness likelihood를 잘 반영하는 Confidence calibration은 여러 응용 분야에서 중요.
- 현대 신경망은 예전과 달리 종종 적절한 보정이 부족한 경우가 있음.
- (= 현대 주요 딥러닝 모델들의 공통점: 크고 넓고 높은 정확도 가짐→but 신뢰도 하락 중)
- 이 연구는 신경망 학습에 대한 통찰력을 제공하며, Platt Scaling의 단순화된 형태인 temperature 조정으로 효과적인 보정을 할 수 있는 방법을 제안.
1. Introduction
- 실제 의사 결정 시스템에서 분류 신경망은 정확성 뿐만 아니라 잘못될 가능성이 높을 때를 나타내야 함.
- 따라서 보정된 신뢰 추정은 모델 해석에도 중요. 좋은 신뢰 추정은 사용자와의 신뢰도를 확립하는 데 유용함.
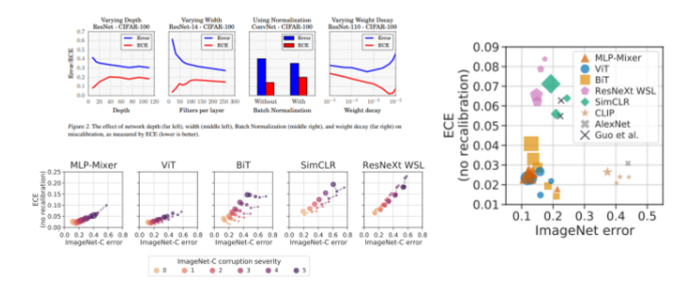
- 최근 연구에서 현대 신경망이 보정되지 않았음을 발견하고, 보정 문제를 해결하는 방법을 찾으려고 함. 여러 컴퓨터 비전 및 NLP 작업에서 신경망이 실제 확률을 나타낼 수 없는 신뢰를 생성함을 보여주며, 이 문제의 원인을 이해하고 있음 ex. 5층 LeNet (왼쪽) vs 110층 ResNet (오른쪽)을 CIFAR-100 데이터셋 비교 결과

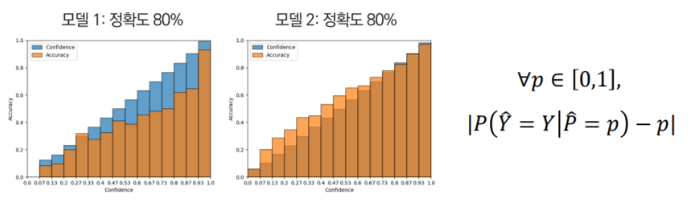
: (Top) LeNet의 평균 신뢰도는 정확성과 근접하게 일치하는 반면, ResNet의 평균 신뢰도는 정확성보다 훨 높음.
: (Bottom) 정확성을 신뢰도의 함수로 보여주는 신뢰도 다이어그램. LeNet은 신뢰도가 예상 정확성과 근사적으로 일치하기 때문에 잘 보정됨. 그러나 ResNet의 정확성은 더 높지만 신뢰도와 일치하지 않음.
4. 다양한 후처리 보정 방법을 비교하고 신경망에서 나온 신뢰를 보정하기 위한 여러 확장을 소개할 것. 그리고 기존 딥러닝 프레임워크로 간단하게 구현할 수 있는 Platt Scaling의 "temperature 조정"이 보통 가장 효과적인 방법 중 하나임을 발견.
문제 정의
- 이 논문에서 주장하는 문제점은 현대 딥러닝 모델들이 Over-confident하다는 것. Confidence란 classification 기준으로 모델이 최종적으로 내뱉은 확률값이라고 생각하면 됨. 이때 모델의 output으로 나온 확률값이 굉장히 높은 값으로 나오게 되는데, 이에 반해서 accuracy는 상대적으로 작은 값을 보인다. 이를 over-confident라고 함.
- 본 논문에서는 모델의 confidence값과 accuracy가 identity하게 대응되도록 함(Well-Calibrated)으로써 reliable한 모델을 만들고자 하였고 이를 Calibration이라고 정의.
- 가장 중요한 점은, 이 논문의 task는 confidence와 accuracy의 값이 대응이 되는 것, 각각의 값들을 높이는 것에 있지 않다는 점.
2. Definitions
Perfect calibration
Reliability Diagrams
ECE (Expected Calibration Error)
MCE (Maximum Calibration Error)
NLL (Negative Log Likelihood)
3. Observing Miscalibration
Model capacity
- Model capacity가 커질수록 ECE가 증가
- 모델은 training loss를 최소화하도록 학습이되고, loss가 줄려면 confidence를 높여서 1에 가까운 값을 예측하도록 해야되기 때문
Batch normalization
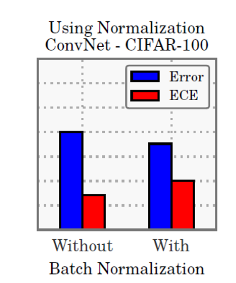
- 본 논문에서도 왜인지는 모르겠다고 하는데, BN을 사용한 모델이 덜 calibrated 됨
Weight decay
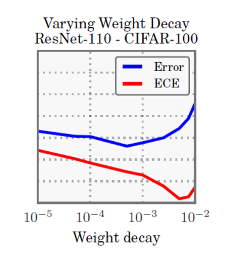
- 최근 연구에 따르면 overfitting 을 막기위해 regularization이 필요하긴 하지만, 작은 weight decay를 쓰는 것이 더 좋은 일반화 성능을 보였다고 함.
- 이러한 최근 연구의 결과와 상통하게, 더 작은 weight decay를 쓸수록 calibration이 잘 안됨
- 마지막에 조금 올라가는 것은 regularization을 너무 세게 해서
NLL
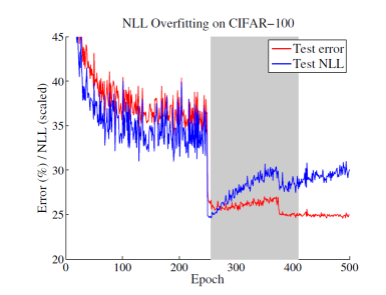
- train 단계에서 NLL에 overfitting 되는게 일반화 성능(test) 향상에 도움이 됨
- capacity가 큰 모형에서는 어느 정도의 NLL에 대한 overfitting이 성능적으로는 긍정적인 것이라고 이해
4. Calibration Methods
binary model에서: Histogram binning, Isotonic regression, Bayesian Binning into Quantiles (BBQ), Platt scaling
multiclass model에서: Extension of binning methods, Matrix and vector scaling , Temperature scaling
위와 같이 많은 방법들 중 본 논문에서는 temperature scaling 사용
Temperature scaling
: Temperature Scaling 기법은 이전에 Hinton 교수님의 Knowledge Distillation에서 처음 사용됨. 이 방법은 모델이 예측한 확률 분포를 더 부드럽게 만들어줌
: Knowledge Distillation에서는 모델이 각 클래스에 대한 확률값을 얻을 때, 단순한 argmax로 hard label을 얻는 것이 아니라, 확률값을 soft label로 부드럽게 만든 후에 사용. 이때 Temperature Scaling이 사용되어 모델의 출력값을 부드럽게 조정.
: 이 논문에서도 모델의 출력값인 로짓(logit)에 Temperature Scaling을 적용하여 확률 값을 부드럽게 만들어서 over confidence 방지. 이러한 조정은 확률값을 부드럽게 하지만, 각 클래스 간의 상대적인 확률 순서는 유지.
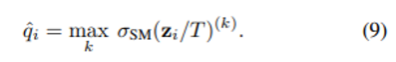
- \hat{q_i}: z_i 라는 logit을 하이퍼 파라미터인 T로 나눈 값을 softmax function에 넣은 값
- T로 scaling을 하든 안하든 softmax 값은 동일하므로 class prediction은 동일해서 model의 accuracy는 영향을 주지 않고, prediction을 calibration만 할 수 있게 해줌
5. Results
- 비교 방법론들에 비해 좋고 매우 빠름. Histogram binning과 isotonic보다는 10배, BBQ보다는 1000배 이상 빠르다고 함.
- temperature scaling은 neural network pipeline에 굉장히 쉽고 직관적으로 구현할 수 있다는 것도 장점.
6. Conclusions
- Model Calibraton: 모델이 갖고 있는 특성 중 하나로, 모델이 출력한 결과와 실제 정확도가 얼마나 비슷한지
- Reliability Diagrams, Expected Calibration Error를 통해 Calibration 관점 성능 평가
- 예측 정확도 성능과 신뢰도 성능 모두 우수해야 실제 산업에서 믿고 사용될 수 있음
- Convolutional Neural Networks: 정확도 성능 ↑, Calibration 성능 ↓
- Non-Convolutional Neural Networks: 정확도 & Calibration 성능 ↑, but 대규모 사전학습 필요
- ex. Self-attention(ViT), Perceptron(MLP-Mixer)연산을 사용하는 모델이 well-calibrated되는 경향