0. Abstract
- 불확실성 하에서의 추론은 기계 학습 시스템에서 중요한 부분
- 예를 들어 Bayesian 방법은 불확실성을 양적화하기 위한 일반적인 프레임워크를 제공하지만, 모델의 오차 추정(model misspecification)과 근사 추론(approximate inference) 사용으로 인해 정확하지 않을 수 있음.
- 이 논문에서는 회귀 알고리즘을 보정(calibrate)하는 간단한 절차를 제안
- 이 절차는 Bayesian 및 확률적 모델에 적용할 때 충분한 데이터가 주어지면 보정된 불확실성 추정을 보장
- 이 방법은 Platt 스케일링에서 영감을 받아 이전의 classification 작업에 대한 연구를 확장한 것
1. Introduction
- 기존 Bayesian 방법의 문제점을 나타내는 그림

-
- 위: interval fails to capture true distribution
- 아래(논문에서 제안하는 방법): recalibrated method
- 논문의 제안점
- 연속형 변수에 대한 불확실성 측정 (uncertainty estimation over CONTINOUS variable)
- Contribution
- 모든 회귀 알고리즘의 출력을 보정하기 위한 간단한 방법론 제안. 이 방법은 이전에 분류에만 적용되던 Platt 스케일링과 같은 보정 방법을 확장
- 이 방법을 사용하여 Bayesian 딥러닝(BNN; Bayesian Neural Network)에서 중요한 문제인 신뢰 구간의 miscalibration 문제를 해결
- 결과적으로 시계열 예측과 모델 기반 강화 학습 분야에서 이 방법론의 유용성 입증
2. Calibrated Classification
전반적인 내용
: 불확실성과 예측 정확도를 다루는 중요한 요소인 Calibrated Classification에 대한 간단한 개요를 제시. 주어진 레이블이 있는 데이터셋 (xt, yt)에서 확률 변수 X, Y에 대해 독립적으로 구성. 예측 모델 H는 입력 데이터 x_t에 대한 레이블 y_t를 대상으로 하는 확률 분포 F_t(y)를 출력. 이진 분류에서 H가 보정되었다는 것은 모든 확률 p ∈ [0, 1]에 대해 실제로 발생하는 사건과 모델의 예측이 일치해야 함을 의미. 모델이 보정되었다고 해도, 예측은 날카롭게 되어야 유용한 예측이 가능. 보다 정확한 예측을 위해 분류 알고리즘을 보정하는 방법들이 있으며, 이를 통해 모델의 예측이 보다 신뢰 가능. 확률 분포를 추정하는 과정을 통해 보정 작업을 수행할 수 있으며, Platt 스케일링은 이러한 보정 기법 중 하나임. 기본 분류기 H가 확률이 아닌 특징 벡터를 출력할 때에도 보정이 가능하며, 특징 벡터에 대한 조건부 밀도를 추정하여 예측을 보정함. 보정된 분류기의 성능은 보정 곡선 및 예측 분포를 통해 평가되며, 이를 통해 모델의 Calibration과 Sharpness을 평가할 수 있음

2-1. Calibration

2-2. Training Calibrated Classifiers

3. Calibrated Regression
전반적인 내용
: 회귀에서 Bayesian 딥러닝 모델 적용. 회귀에서 보정은 $y_t$가 대략 90%의 신뢰 구간에 약 90%의 시간 내에 속해야 함을 의미. 미래 데이터 크기가 무한대에 접근할 때 경험적인 CDF와 예측된 CDF가 일치해야 함을 의미. 또한 보정이 있더라도 예측은 날카로워야 유용함. 회귀 context에서 sharpness는 신뢰 구간이 단일 값 주변에 가능한 한 타이트해야 함을 의미하며, 예측된 CDF의 분산 var(F_t)이 작아야 합니다.
이 논문에서는 사전 훈련된 예측 모델 H를 사용하여 보정된 예측을 생성하는 간단한 보정 방법을 제안. 이 방법은 충분한 i.i.d. 데이터가 주어지면 보정된 예측을 생성하며, Bayesian 알고리즘을 포함한 모든 회귀 모델에 적용할 수 있다고 함. 기존 방법들과의 차별점은 기존 방법들은 예측 모델을 수정해야 하고 충분한 양의 데이터가 주어지더라도 보정된 예측을 생성하지 못했었음. 또 회귀 예측 모델의 품질을 정량화할수있는 calibration과 sharpness를 평가하는 진단 방법 제안.

3-1. Calibration
regression에서 calibration의 의미

3-2. Training Calibrated Regression Models
simple re-calibrated scheme을 제안

3-3. Recalibrating Bayesian models

3-4. Features for Recalibration
[Algorithm 1]을 사용하여 recalibration을 진행할 수 있음.

3-5. Diagnostic Tools

4. Experiments
전반적인 내용
: 실험 setting과 그 결과들. Depth estimation, time series forecasting, model-based reinforement learning에서 모두 좋은 결과를 보임
4.1. Setup
- 데이터셋: UCI 데이터셋 8개를 사용하며, 무작위로 데이터를 분할하여 5회 반복 실험을 실시. Make3D 데이터셋을 사용하여 depth estimation 실험을 수행함.
- 모델: Bayesian Ridge Regression, 피드포워드 및 순환 신경망, 그리고 Gal과 Ghahramani (2016a)의 dropout 근사법을 사용하여 예측 모델을 고려. UCI 실험에서는 피드포워드 신경망과 순환 신경망을 사용하며, 특정 아키텍처와 하이퍼파라미터를 설정
- 벤치마크: 딥 러닝 모델의 보정을 향상시키기 위해 최근에 제안된 두 가지 방법과 비교함. Concrete dropout은 dropout 확률을 학습하기 위한 기술, deep ensembles는 여러 모델을 훈련하고 예측 분포를 평균화하는 방법
4.2. UCI Experiments
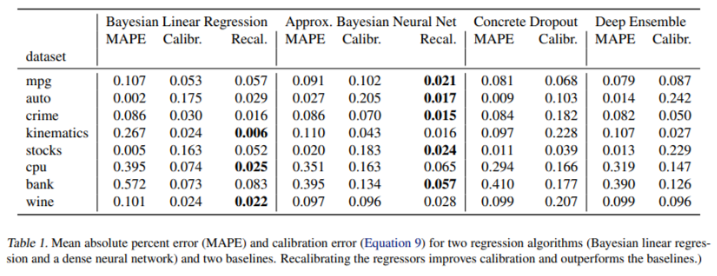
4.3. Depth Estimation

드롭아웃을 사용하여 픽셀 단위의 불확실성 추정을 계산하고, 훈련 세트의 모든 픽셀에서 보정.
보정 오차가 크게 개선되면서 정확도는 유지
4.4. Time Series Forecasting
시계열 예측도 보정 잘함

4.5. Model-Based Reinforcement Learning
강화학습도 보정 잘함
