Abstract
- 본 연구가 다루는 Task는 다변량 시계열 예측
- 대조학습과 트랜스포머 기반 모델이 좋은 성능을 거뒀었지만 몇 가지 문제점 존재
- 대조학습 기반 사전학습과 Downstream 예측 Task가 Inconsistent함
- 트랜스포머 기반 모델은 심각한 Distribution shift 문제를 야기하게 되고, 자기지도 학습 방법들에 비해 시퀀스 정보를 제대로 활용하지 못함
- Ti-MAE는 완벽한 distribution을 따르도록 입력 시계열이 가정되어 있음
- 시계열 일부를 마스킹하고 point-level에서 재복원하는 모델
- 마스크 모델링을 auxiliary task로 채택하고 기존의 표현학습과 생성 트랜스포머 기반 방법론을 연결하여 upstream과 downstream 예측 task의 차이를 줄임
- 실험 결과 강력한 표현을 학습할 수 있었음
Introduction
시계열 모델링은 여러 분야로 활용될 수 있는데, 최근 관심받는 어려운 Task는 **Long sequence time series forecasting (LSTF)**이다. 이는 장기간에 걸쳐 시계열의 변화를 예측하는 것을 목표로 한다.
⇒ 목적: 마스킹 하여 잘 예측하게 해서 장기 시계열 예측성공하는 것
<방법들>
- self supervised representation learning
- LSTF 문제점
- Augmentation으로 인해 생기는 불가피한 왜곡 외에도, upstream 대조학습 접근법과 downstream 예측 Task 사이의 Inconsistency 또한 큰 문제이다.
- 또한 최근에 밝혀진 것으로는 self supervised learning 관점에서는 Transformer가 CNN보다 덜 consistent하다는 문제가 있다
- LSTF 문제점
- 시계열에서 self supervised representation learning은 변형과 관계없이 불변하는 피쳐를 학습하고자 하는데, 시계열 분류에서는 괜찮은데 시계열 예측에서는 아직 해결되지 않은 문제들이 있다.
- Contrastive learning 대안책
- 대조학습의 대안책으로 Denoising autoencoders가 auxiliary task로 사용될 수 있다.
- 기존 트랜스포머 기반 학습 패러다임은 아래 그림과 같은데, 이는 장기간 의존성을 포착하는 것을 목표로 한다. 방법은 과거 시계열 데이터로부터 유사한 패턴을 학습하여 미래 시계열을 예측하는 것이다..

-
- 위 방법은 generative Transformer-based 모델로 Denoising autoencoder의 특수한 경우로 볼 수 있다.
- 오직 미래 값을 마스킹(연속적인 미래값 전부 마스킹)하고 이를 복원하는 전략을 택하는 것이다.
- 문제점
- 해당 방법에는 몇 가지 심각한 문제가 있다.
- 두 번째로, 연속적인 마스킹 전략은 심각한 distribution shift 문제를 야기할 수 있고, 특히 예측 구간이 입력 시퀀스보다 길 때 발생한다.
- 문제점
- Decomposition방법
- 이전 연구들에서는 시계열을 Trend와 Seasonality 파트로 나눠서 주기적인 피쳐를 더 잘 포착하고 Outlier 노이즈에 강건하도록 했다.
- 특히 Moving average를 사용해서 Trend 정보를 얻고, 원본 시계열에서 Trend를 차분하여 Seasonality를 계산하는 전략을 택했다.
- 하지만 해당 전략도 시퀀스의 양 사이드에 패딩을 해서 alignment를 해주어야지만 MA가 계산이 되었고, 이는 불가피한 데이터 왜곡을 낳았다.
- Contribution
따라서 본 연구는 위 그림과 같이 Ti-MAE를 제안하여 embedded 시계열에 랜덤하게 마스킹하고, point-level에서 이들을 복원하는 방법론을 제시한다.
랜덤 마스킹은 입력 데이터의 전체 분포를 반영할 수 있기 때문에, distribution shift 문제를 완화할 수 있다.
Related Work
Transformer-based Time Series Model
트랜스포머 기반 시계열 모델들은 long-range 의존성을 포착하는 능력이 있다.
하지만 vanilla 트랜스포머를 그대로 적용하기에는 계산량이 너무 많다.
그래서 sparse attention 매커니즘을 사용하려 했는데 그러다보니 예측 정확도가 떨어진다.
그래서 ETSformer나 FEDformer는 disentanglement에 크게 의존하는데 이는 도메인 지식이 추가로 필요하다.
Time Series Representation Learning
시계열 도메인에서 자기지도 표현학습은 좋은 성능을 거뒀고, 특히 대조학습을 통해 좋은 표현을 학습할 수 있었다.
대표적인 모델은 CPC, InfoNCE 등이 있고, 같은 시퀀스로부터 뽑힌 데이터는 positive pair로 미니배치 안의 다른 noise data는 negative pair로 처리한다.
시계열에서 자기지도 표현학습을 제대로 사용하기 힘든 이유는 너무 data augmentation에 의존을 많이 하고, 계층구조나 disentanglement와 같은 도메인 지식에 의존을 많이 하기 때문이다.
Masked Data Modeling
NLP 특히 BERT 모델이 성공했다. 입력 시퀀스의 일부를 지우고, 삭제된 정보를 예측하도록 학습을 하면 좋은 표현을 만들어낼 수 있다는 것이 그 아이디어이다.
해당 아이디어를 이미지 분야에서 그대로 활용한 것이 MAE이다.
MAE는 높은 비율로 패치를 마스킹하고, 이를 재복원하도록 하여 표현을 학습하게 된다.
위 아이디어들에 영감을 받아 Ti-MAE는 조금 더 long time 의존성을 모델링할 수 있도록 MAE 학습 방식을 변형하였다.
Methodology
문제 정의
다변량 시계열 데이터이며, 예측이라면 다음 k step의 값을, 분류라면 시계열마다 부여된 클래스 라벨 C를 예측하도록 문제가 정의된다.
Model Architecture
모델의 전체적인 구조는 위 그림과 같다.
오토인코더 구조를 띄고 있기 때문에, 인코더에서는 입력 신호를 잠재 표현으로 매핑하고
디코더에서는 잠재 표현을 통해 입력 신호를 재복원한다.
MAE 구조를 차용하고 있기 때문에 인코더에서는 마스킹 되지 않은 부분만 입력으로 사용하고,
디코더에서는 전부 사용하되 인코더보다는 가벼운 네트워크 구조를 갖게 된다.
Input embedding
위 그림에서 Input embedding으로 나타나있는 Block은 간단한 1-D Convolutional layer이다.
어떠한 multi-scale 또는 복잡한 convolution 형태(ex. dilated convolution)를 지니지도 않았다.
Position 정보를 주기 위해 positional embedding을 추가하는데, 이 또한 task-specifc하거나 date-specific한 정보는 주지 않음으로써 최소한의 inductive bias만 부여했다.
Masking
MAE 방법과 동일하게 비복원추출로 랜덤하게 샘플을 골라 마스킹한다. 랜덤하게 추출될 확률은 Uniform distribution을 따르도록 한다.
마스킹 비율은 information density와 redundancy에 연관이 있는데,
일반적으로 information density가 낮은 데이터는 높은 마스킹 비율을 적용해야 한다.
본 연구에서 사용되는 시계열 또한 local continuity가 존재하여 information density가 낮기 때문에
저자는 **최적 마스킹 비율을 75%**로 제안한다.
Ti-MAE Encoder
인코더에는 vanilla 트랜스포머 블록 구조를 사용한다. 차이점은 post-norm 대신 pre-norm layer를 사용한다는 점이다.
MAE와 동일하게 visible 토큰만을 처리하며, 이는 시간 복잡성과 메모리 사용량을 크게 줄일 수 있다.
Ti-MAE Decoder
디코더도 vanilla 트랜스포머 블록 구조를 사용하는데, 인코더보다 훨씬 작고 encoded visible token과 learnable randomly initialized mask token 모두를 처리한다.
빠진 부분을 패딩한 후 positional embedding을 모든 토큰에 추가한다.
마지막 layer는 linear projection layer로 point-level에서 모든 값을 예측하도록 한다.
손실함수는 MSE를 사용한다.
Ti-MAE의 인코더와 디코더 모두 sequential data에 agnostic하게 구성됨으로써 domain knowledge를 최소로 필요하도록 한다. 여기에는 date-specific embedding, hierarchy, disentanglement 등이 필요하지 않게 된다.
Experiments
실험은 시계열 예측과 분류 모두 진행되었으며 사용된 데이터셋은 다음과 같다.
- ETT
- Weather
- Exchange
- ILI
- UCR archive
ETT만 6:2:2 비율로 학습, 추론에 사용되었으며, 나머지는 7:1:2 비율로 사용되었다.
UCR 데이터셋을 시계열 분류 실험에 사용했다.
Baseline 모델은 Transformer-based end-to-end 모델들과 표현학습 모델들로 나뉜다.
먼저 시계열 예측 Task는 표현학습 모델 CoST, TS2Vec, TNC, MoCo / Transformer-based end-to-end 모델 FEDformer, ETSformer, Autoformer, Informer가 사용되었다.
다음으로 시계열 분류 Task는 TS2Vec, T-Loss, TS-TCC, TST, TNC, DTW가 사용되었다.
성능지표는 예측 문제는 MSE와 MAE / 분류 문제는 critical difference와 함께 average accuracy가 사용되었다.
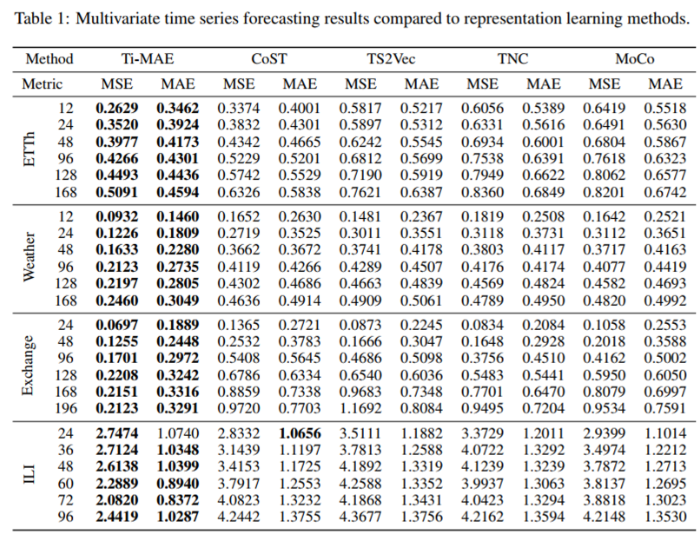
다양한 예측구간으로 시나리오를 나누어 다변량 시계열 예측 Task를 수행한 결과
제안하는 Ti-MAE 방법이 가장 우수했다.
Ti-MAE는 추가적인 regressor가 필요하지는 않다. 디코더 부분에서 이미 예측을 수행하도록 되어있기 때문.
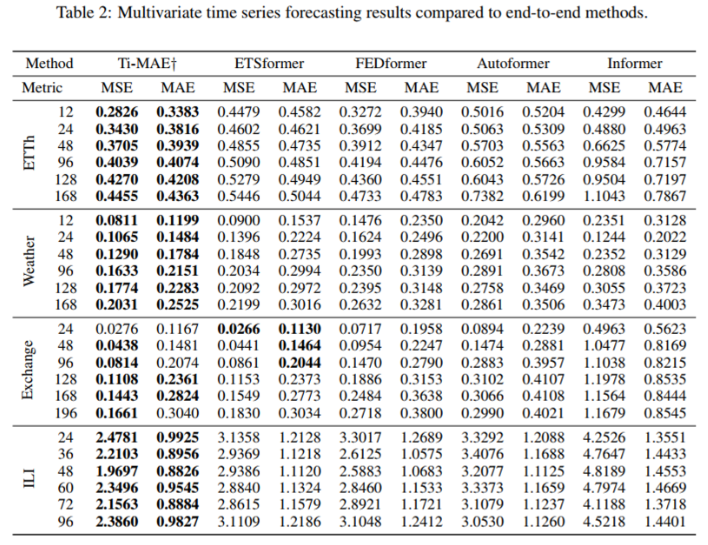
그래도 Fine-tuning을 하면 위 표처럼 성능 향상이 살짝 더 존재한다.
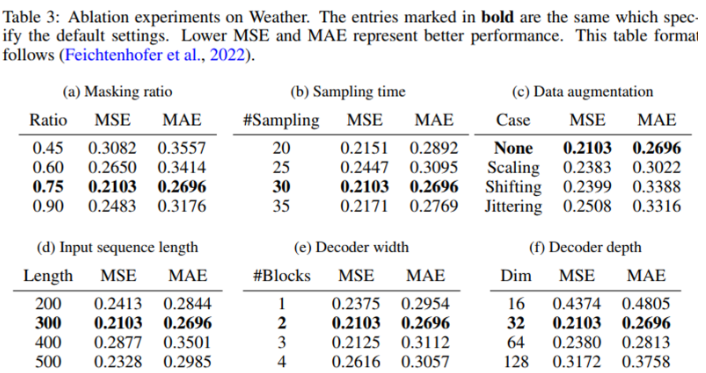
Weather 데이터셋에 대해 Ablation study를 진행한 결과는 위와 같다. 75% 마스킹 비율이 가장 우수했으며, 디코더는 그렇게 깊고 넓게 쌓을 필요가 없음을 나타낸다. Data augmentation이 존재하지 않을 때 가장 우수한 것을 알 수 있다.
마스킹 비율이 낮을 때는 값을 복원할 때 interpolation이나 extrapolation의 영향을 더 받게 되는데 이는 low level semantic feature에만 지역적으로 집중하기 때문에 좋지 않다.
너무 긴 입력 시퀀스는 오히려 성능을 떨어뜨릴 위험이 있는데, upstream에서 포착한 복잡한 패턴이 downstream에서의 짧은 시계열 예측에는 안 좋을 수 있기 때문이다.
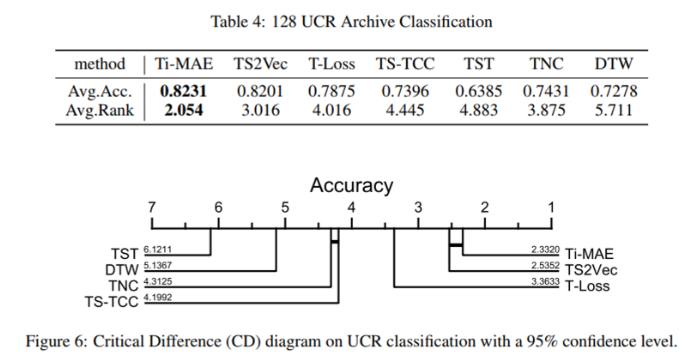
시계열 분류 Task는 UCR 데이터셋을 사용해서 이뤄졌는데, 역시나 제안하는 방법이 제일 좋다.
Conclusion
Ti-MAE는 시계열에서 point-level로 랜덤하게 마스킹하고 복원하는 방식으로 표현을 학습했다.
대조학습 형태의 표현학습과 generative Transformer-based 방법론들 사이를 연결하고 upsteram과 downstream task간의 inconsistency를 줄여 예측 성능을 높였다.
모든 입력 시퀀스를 사용했으며, distribution shift 문제도 해결했다.
Future work는 다양한 reconstruction target을 사용해보는 것이다.