📌 본 내용은 Michigan University의 'Deep Learning for Computer Vision' 강의를 듣고 개인적으로 필기한 내용입니다. 내용에 오류나 피드백이 있으면 말씀해주시면 감사히 반영하겠습니다. (Stanford의 cs231n과 내용이 거의 유사하니 참고하시면 도움 되실 것 같습니다)📌
(📁 아래에 똑같이 제가 정리해놓은 블로그 참고..! 벨로그에 있는게 더 상세히 정리 잘 되어있습니다)
https://velog.io/@ha_yoonji99/Michigan-DLcs231n-11%EA%B0%95-Training-Neural-Networks-Part2
[Michigan DL/cs231n] 11강: Training Neural Networks (Part2)
🔥Michigan University Deep Learning 11강🔥
velog.io
1. Learning Rate Schedules
1) 비교
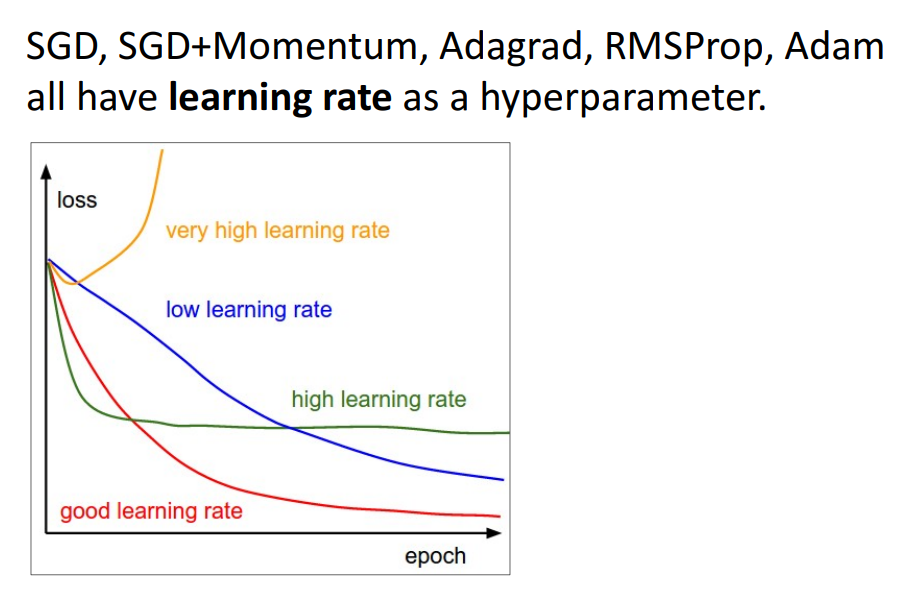
- 해석
- very high LR: loss가 급증함
- low LR: 매우 천천히 학습 진행
- high LR: 매우 빨리 수렴하지만, loss가 덜 낮아짐
- good LR: 적당
- 질문
- Q. 어떤 LR이 가장 사용하기 적절한가?
- A. 다 ㄱㅊ음! high LR부터 시작해서 줄여가보자.
- = LR Schedule 이라고 함
2) LR Decay
a. Step Schedule
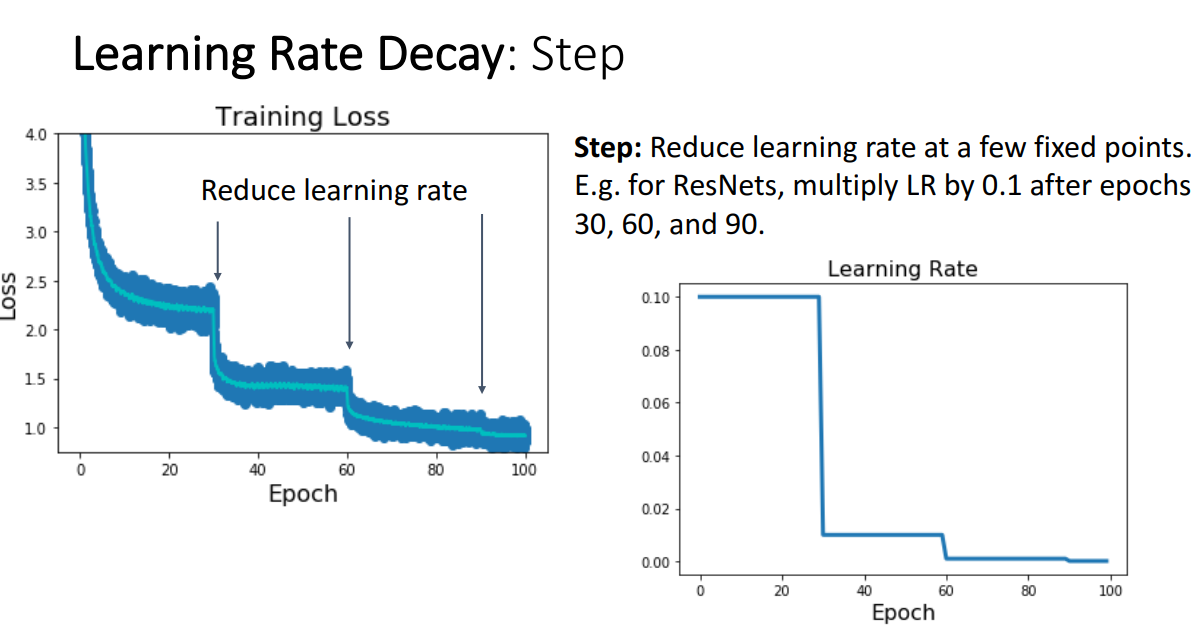
- 개념
- 고정된 point들에 LR을 감소해줌
- ex. ResNet → 0.1부터 시작해서 30 epoch마다 0.10.1, 0.10.1*0.1 이런식으로 줄임
- 문제점
- trial & error가 너무 많음
= train model 에 너무 많은 새로운 hyper parameter넣음
= 너무 많은 경우의 수를 생각해서 tuning 해야됨
= LR을 decay할 특정 지점 선택해야됨
⇒ 몇번 반복시마다 LR줄일건지 & 어떤 LR로 줄여나갈건지 결정해줘야 됨
- trial & error가 너무 많음
b. Cosine Schedule
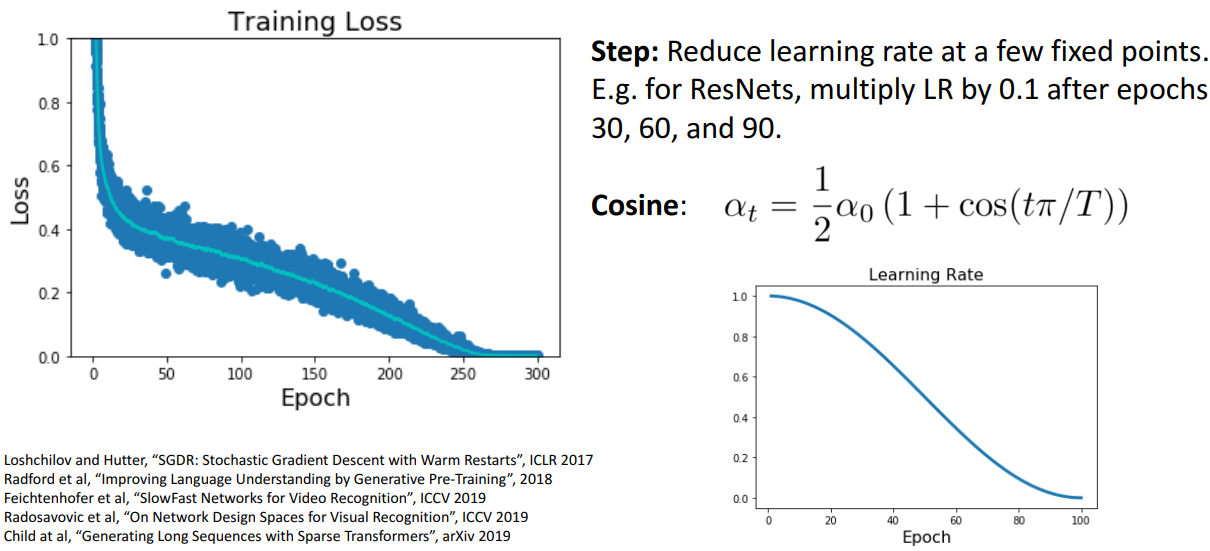
- 개념
- LR을 decay할 특정 지점 설정하는 대신, 초기 LR만 설정
- 기존보다 매우 적은 hyperparameter로 train하기 더 쉬움
- train longer ↑ → 성능 ↑
- LR을 decay할 특정 지점 설정하는 대신, 초기 LR만 설정
- 해석
- 절반쯤에 LR이 떨어짐
= 첨에 LR 높게 시작하고, train 끝쯤에 LR이 0에 가까워짐
- 절반쯤에 LR이 떨어짐
- 문제점
- 계산 복잡도 올라감
c. Linear Schedule
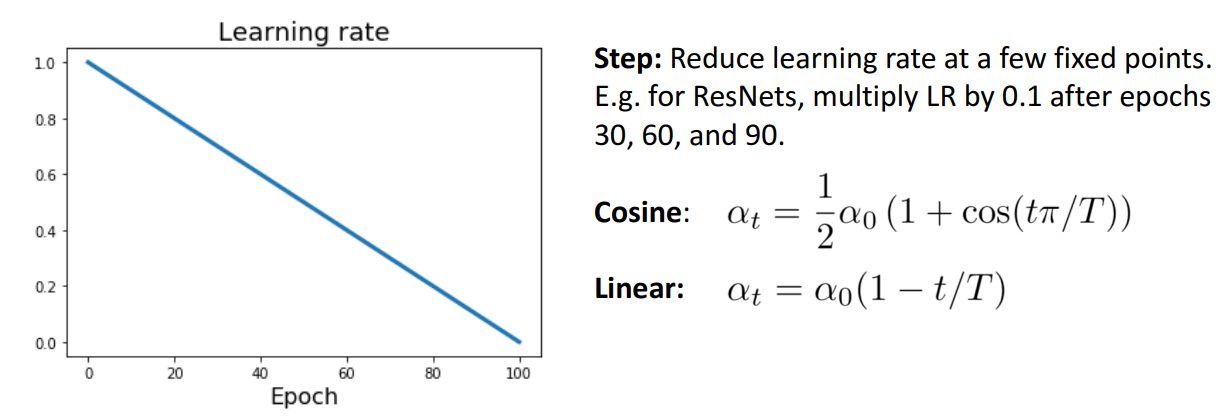
- 개념
- 기존보다 simple함
- cf) cos과 linear중에 뭐가 더 나은지는 연구가 적어서 말하기 애매함.
- domain별로 선호하는 LR schedule 존재
- cv : cos schedule 선호
- NLP: linear 선호
- domain별로 선호하는 LR schedule 존재
d. Inverse Sqrt Schedule
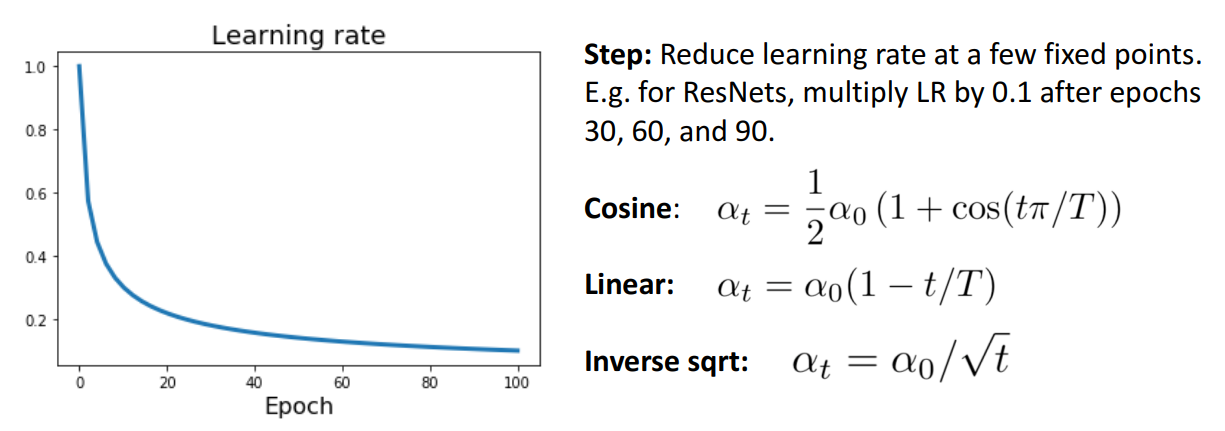
- 개념
- square root 사용
- 문제점
- 초기 high LR에서 갑자기 확 줄어듦
e. Constant

- 개념
- 젤 흔함
- 생각보다 잘 적용됨 (걍 이거 사용해도 ㄱㅊ음)
- 더 복잡한 schedule로 갈수록, 몇% 더 좋은 성능
- 기존 Schedule과의 차이
- 모델 work/not work에서 차이X
- constant → 더 복잡한 schedule로 갈수록, 몇% 더 좋은 성능
- 걍 모델이 work만 되게 하면 되면, constant가 괜찮은 선택
- cf) SGD+Momentum → LR decay schedule 선택 중요
RMSProp or Adam → 걍 constant 써도 ㄱㅊ
- 관련 질문
- Q. Loss가 높아졌다 낮아졌다 다시 높아지는 경우가 있나요?
A. 있음. zero-grad가 되는 경우를 고려하지 않을때, task의 type에 따라 bad dynamic을 볼 수도 있다. data corruption이 explode를 유발 가능하다
(일반적인 답은 아님, 사바사)
3) Early Stopping
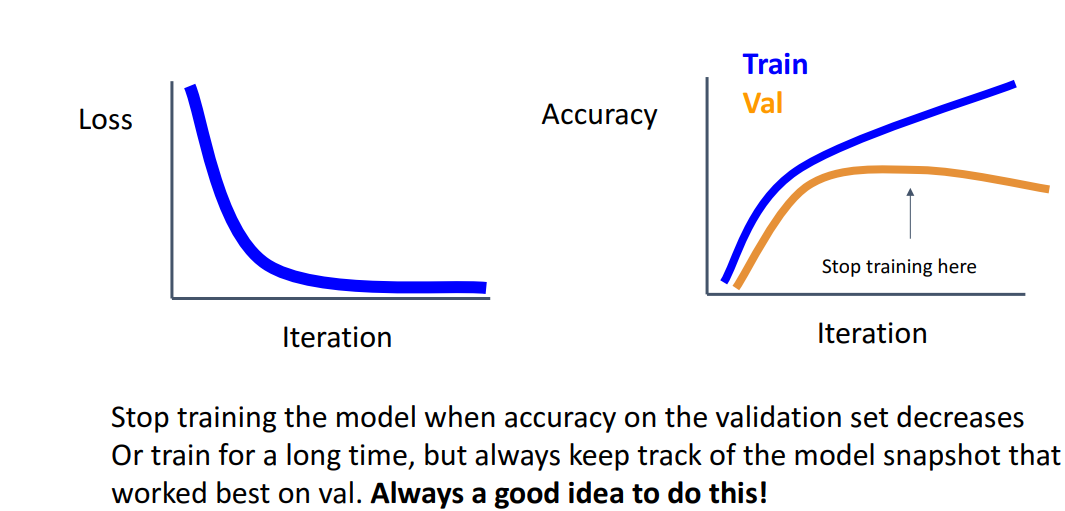
- 개념
- val의 accuracy가 감소하려할때 (overfitting 전) 반복 중지시켜야됨
- 매 iteration마다의 model snapshot저장후, val set에서 가장 잘 work시의 weight가져옴
- val의 accuracy가 감소하려할때 (overfitting 전) 반복 중지시켜야됨
2. (GPU多) Choosing Hyperparameters
📍 Grid, Random Search
1) 방법
a. Grid Search

- 개념
- 미리 정해진 숫자들
b. Random Search

- 개념
- 범위 내의 랜덤한 숫자들
2) 비교
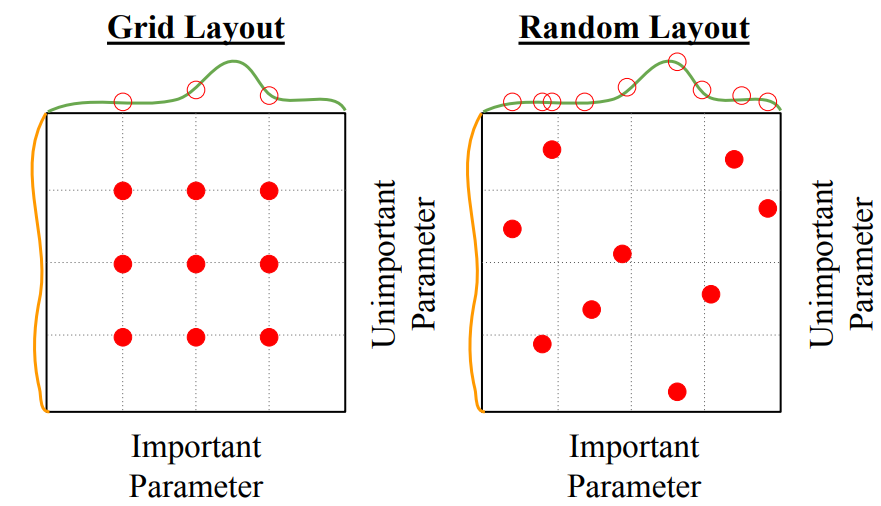
- 해석
- Grid Search: 중요 파라미터들을 덜 잡아냄
- Random Search: 중요 파라미터들을 더 많이 잡아냄
3) Random Search Weight decay
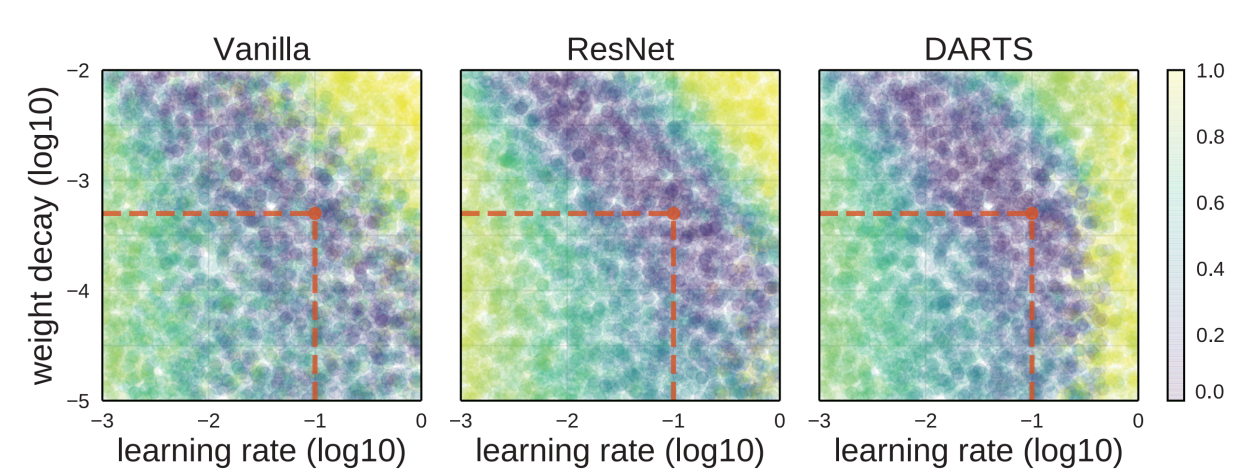
3. (GPU 無) Choosing Hyperparameters
📍 총 7step 과정
1) 과정
a. 초기 loss 측정
- weight decay 설정 안한 상태에서, 맨 처음 loss 확인
ex. softmax → 맨 처음 loss값이 logC가 아니면, 네트워크 오류있음
b. 작은 sample을 overfit해보기
- 작은 training set (5~10 미니배치)에서 100% accuracy가 나오는지 확인
- loss가 잘 안떨어지면, LR, weight initialization 고려
c. loss가 줄어드는 LR찾기
- Step2의 architecture 고정 후, 모든 train data 활용하여 100 iteration동안의 LR시도
→ loss가 줄어드는 LR 찾기
d. epoch 1~5번 돌려보며, weight decay 조정
- 여기서 엄청 낮은 성능을 얻을리X
e. Refine grid, train longer
- Step4에서 고른 모델 epoch 늘려서 train시킴
→ 엄청 오래걸릴수도
f. Learning curve 확인하기
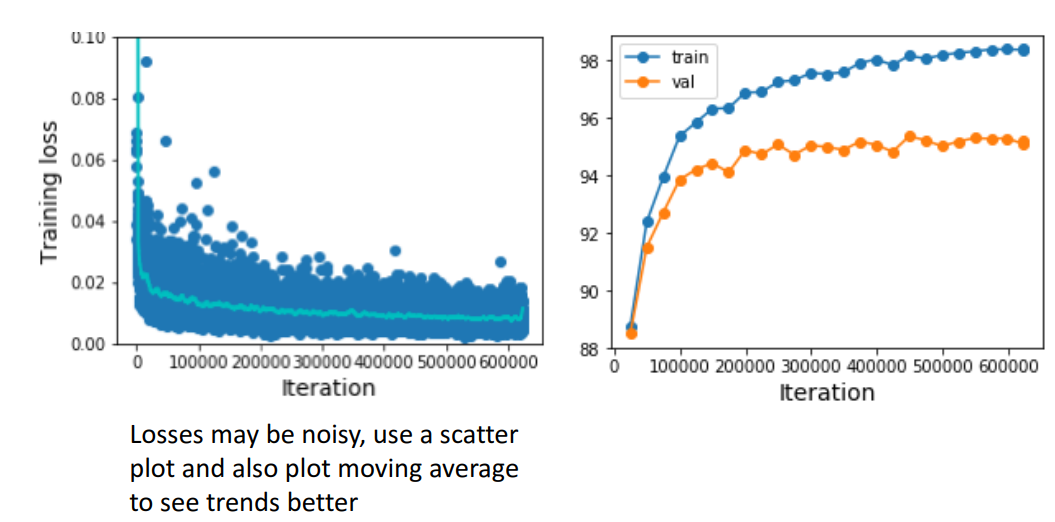
- train loss → 움직이는 손실평균
- train loss
-
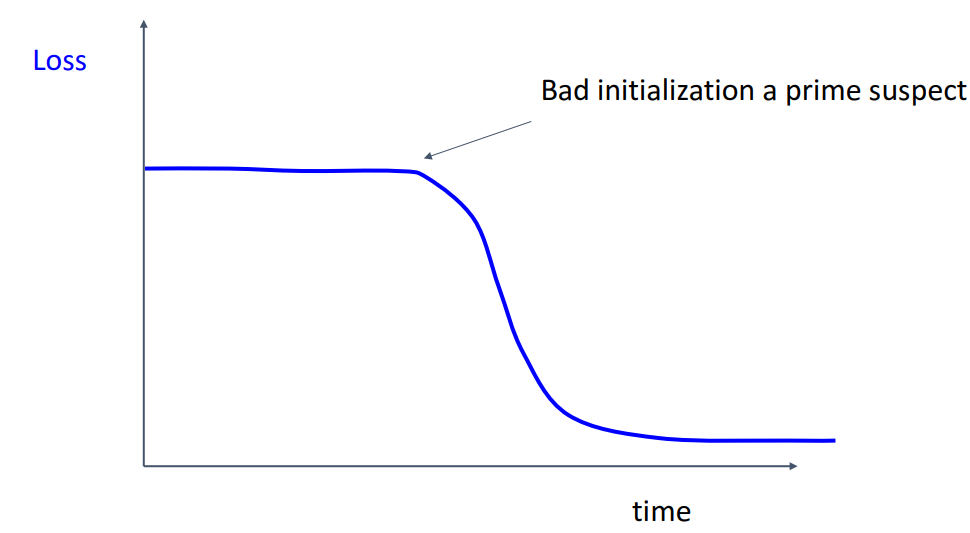
- **해석**
- **loss가 처음에 평평하다가 갑자기 감소**
= **weight 초기화**가 좋지 않음 (train 초기에 진전이 없어서)
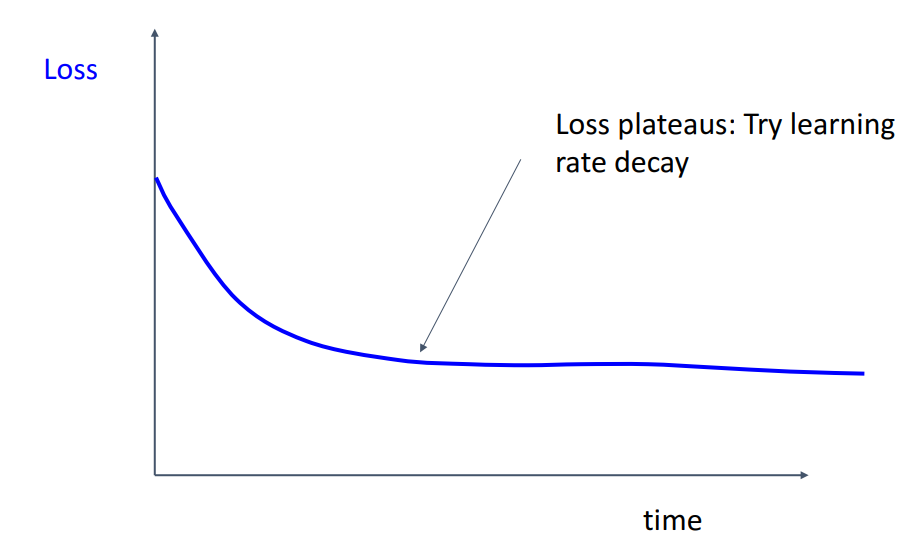
- **해석**
- **loss가 감소하다가 더 떨어질 가능성 있지만 안떨어짐**
= **LR 설정** 좋지 않음 (LR이 너무 높았을것)
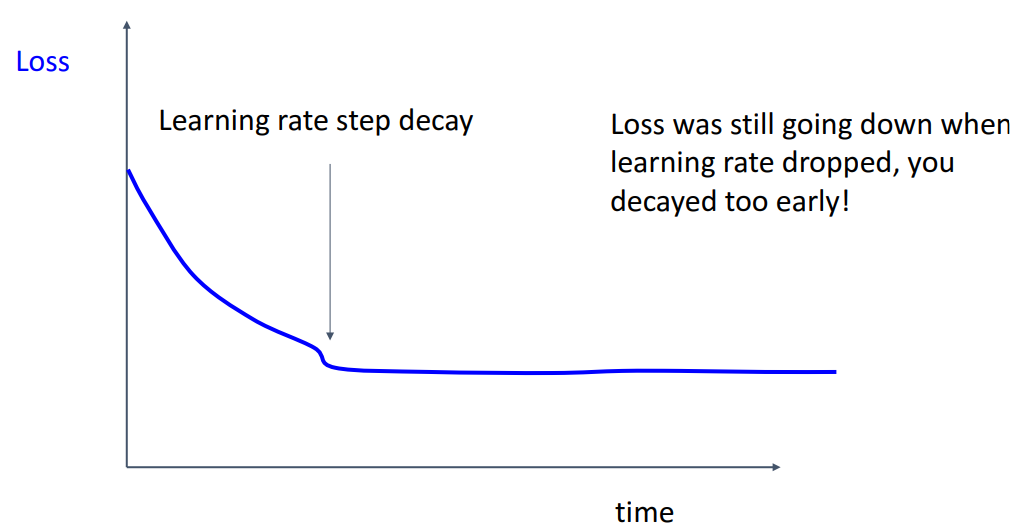
- **해석**
- **너무 빨리 LR을 줄인 경우**
= loss가 **flat해지는 지점까지 기다렸다가 decay**하기- train, val accuracy
-
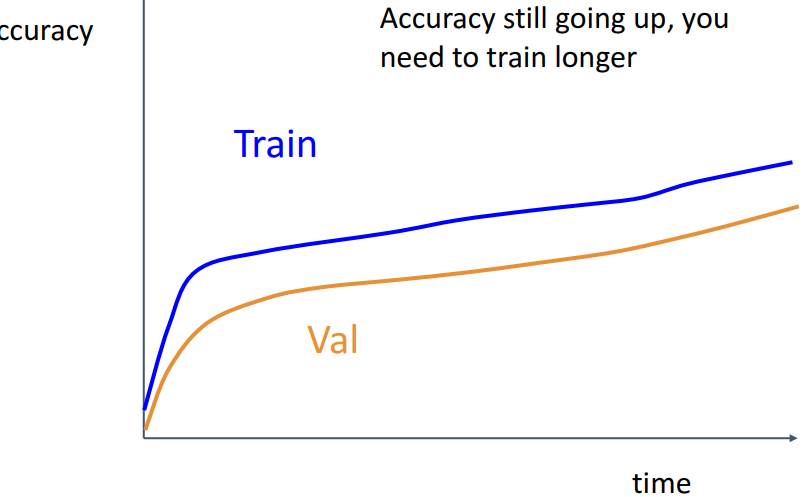
- **해석**
- **train과 val의 accuracy가 같이 증가 & 적당한 차이 유지**
→ **해결) train 더 시키면 됨**
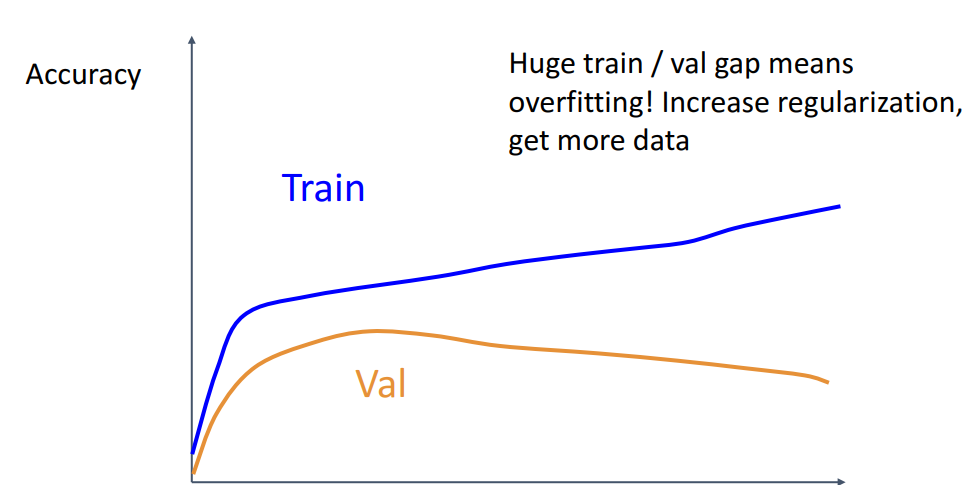
- **해석**
- **train과 val gap이 갈수록 커짐 = 오버피팅**
→ **해결) regularization ↑***(=L2 규제에서 $\lambda$를 더 크게 지정 or data augmentation)***, data 더 모으기**
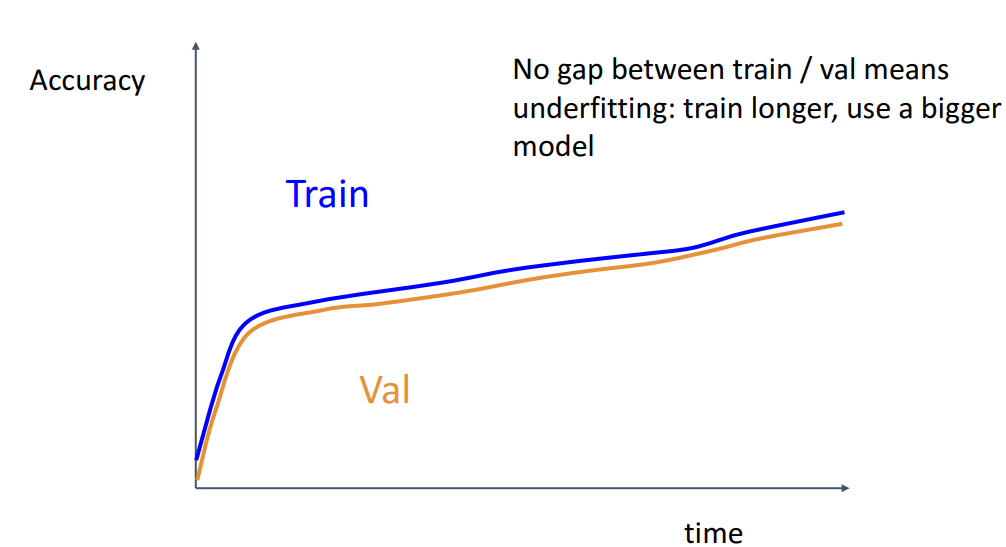
- **해석**
- **gap이 거의 없음 = 언더피팅**
**→ 해결) train longer, 더 큰 모델 사용** g. GOTO step5
- 하이퍼파라미터 조정 반복
- LR, LR decay schedule, update type
- regularization(L2, Dropout strength)
4. After Training: Model Ensemble (Tip&trick: LR schedule, polyak averaging)
📍 앙상블, transfer learning, large-batch training
1) Model Ensembles
- 개념
-

- multiple 서로 다른 모델들 학습
- 학습 결과를 test time에 평균내기
- 앙상블 하면 **2%정도** 성능 올라감- Tips & Tricks (하나의 모델로 앙상블 효과 내기)
- 방법
- LR schedule 활용하기
-
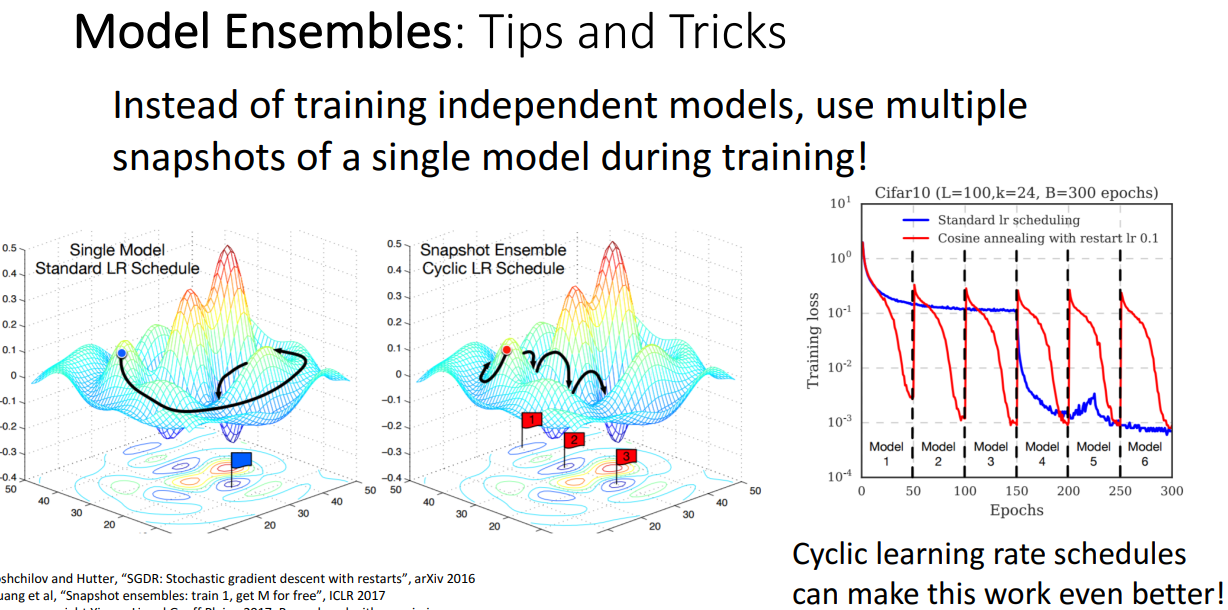
- 방법
: LR decay 주고, 특정 시점마다 다시 LR 높게 주면서 구간별 모델의 snapshot을 저장하여 모델이 낸 결과를 평균내어 앙상블 구현
- **Polyak averaging**

: train 후의 파라미터가 아닌, **train 시의 파라미터** moving average(x)를 test에 활용5. After Training: Transfer Learning
📍 feature extract, fine tuning
1) 발생 배경
- CNN에서 많은 데이터가 필요하다는 문제에 해결책 제시
2) CNN에서 적용해보기
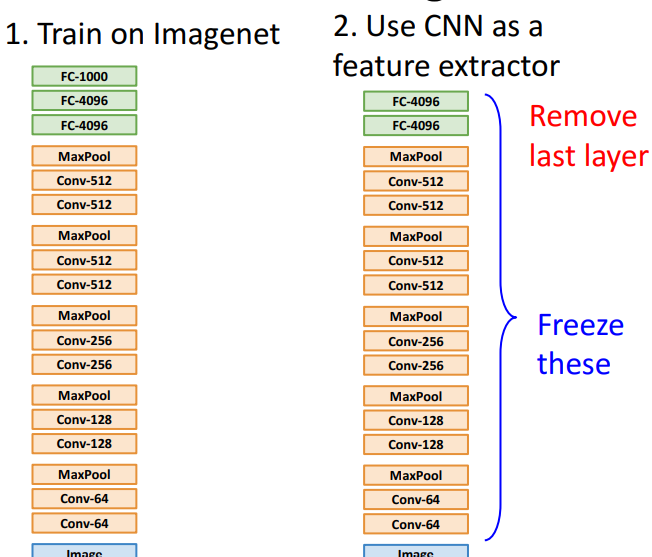
- 개념
- dataset이 작다면 매우 효과적
- CNN을 feature 추출기로 만들고 → 그 위에 linear 분류
- 사용 예시
- feature를 우리가 신경쓰는 어떤 작은 data set에 적용 (=이미지넷의 1000개 카테고리 분류대신, 10개의 종류 분류정도만 하고 싶은 것)
→ 행렬 임의로 재초기화 (ex. imageNet: 40961000, 새로운 class: 4096c10)
→ *(Freeze these)** 모든 이전 계층의 가중치 고정
→ 선형 분류기 훈련
→ 마지막 계층 파라미터들만 훈련
→ 데이터에 수렴
- feature를 우리가 신경쓰는 어떤 작은 data set에 적용 (=이미지넷의 1000개 카테고리 분류대신, 10개의 종류 분류정도만 하고 싶은 것)
- 성능 비교 예시
-
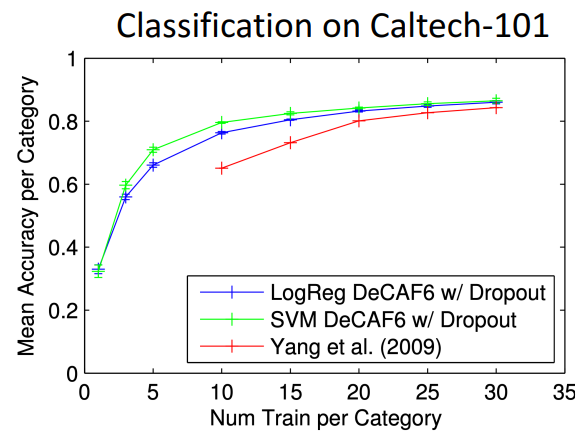
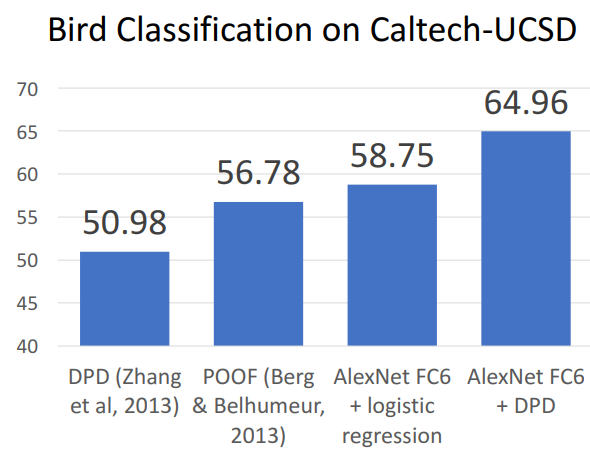
- **해석**
- Alexnet feature들을 이전 방법에 적용시키면 더 좋은 성능
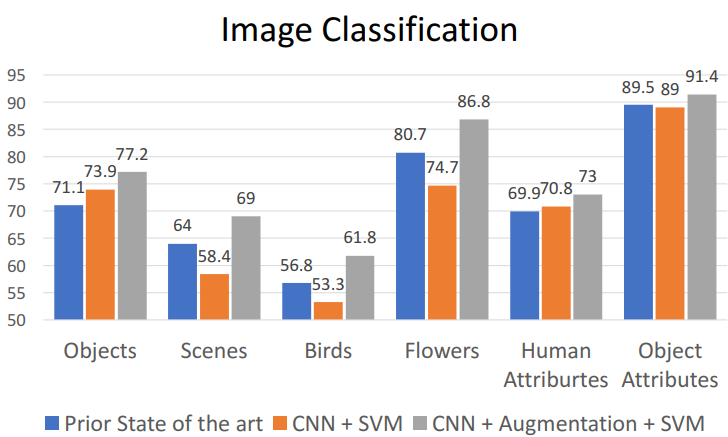
- **해석**
- **imageNet에서 feature추출한 pretrained model로 → feature벡터위에 NN적용**
= transfer learning으로는 젤 간단한 예시 (단순히 feature vector추출하고 사용)
- 최근접이웃 방법으로 image 복구작업 수행3) Bigger dataset: Fine-Tuning

- 개념
- 마지막 layer버리고, 새 layer(새로운 데이터셋의 분류 category와 관련되도록 초기화)로 대체
= 모델 전체를 새 분류 dataset에 맞춰 다시 학습 - 고정된 feature 추출기X, 실제 모델로 역전파하며 모델 가중치 계속 update → downstream에서의 성능 개선
- 마지막 layer버리고, 새 layer(새로운 데이터셋의 분류 category와 관련되도록 초기화)로 대체
- downstream 성능 향상 위한 trick & tips
- 먼저 feature extraction → 그 위에 linear model학습 → 전체 모델 다시 fine tuning
- fine tuning진행 시, LR을 크게 감소시켜야 할수도 있음
- 컴퓨팅 비용을 아끼기 위해 low layer를 freeze해라.
- 성능 비교
-
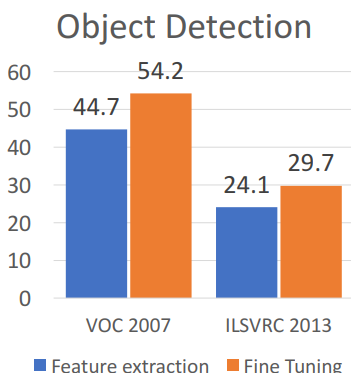
- **해석**
- **고정된 Feature Extraction:** 전체 network freeze하고 **feature extraction**으로만
- **fine tuning: 새로운 dataset**에 대해 전체 신경망 모델 계속 학습 → 성능 더 ↑6. After Training: Transfer Learning_Architecture Matters & 특징 일반화
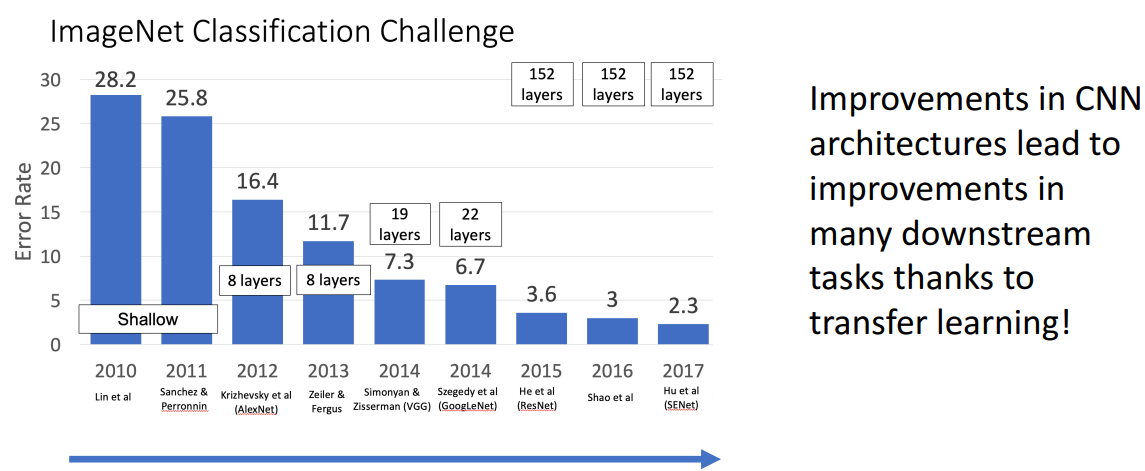
- 해석
- imageNet에서 잘되면 다른 데서도 잘됨
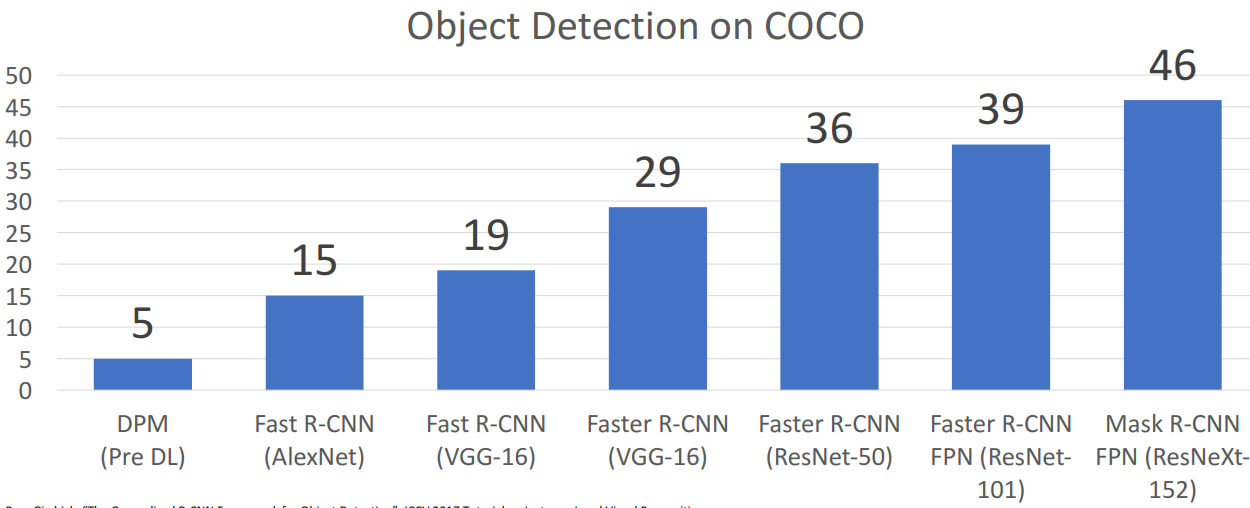
- 예시
-
1) Transfer Learning 특징 일반화
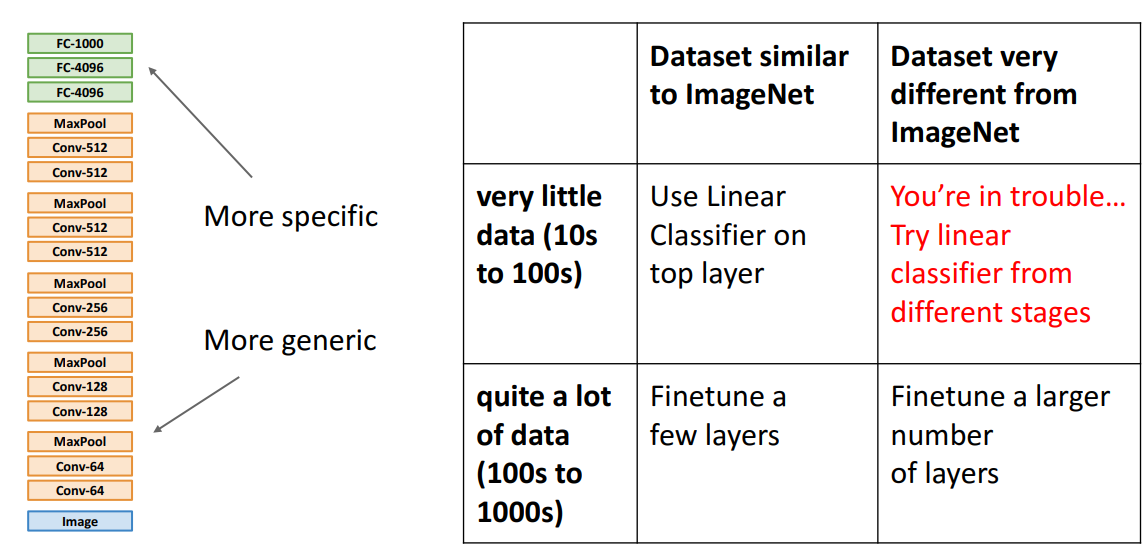
| 매우 비슷한 dataset | 매우 다른 dataset | |
|---|---|---|
| 매우 적은 data | 제일 윗계층에서 linear classifier사용 | 곤란한 상황, 여러 단계로부터 linear classifier 시도 |
| 꽤 많은 data | 몇개의 layer 미세조정 | 더 많은 계층 fine tuning |
2) 전이학습 활용 예시들
a. 물체 인식, image captioning
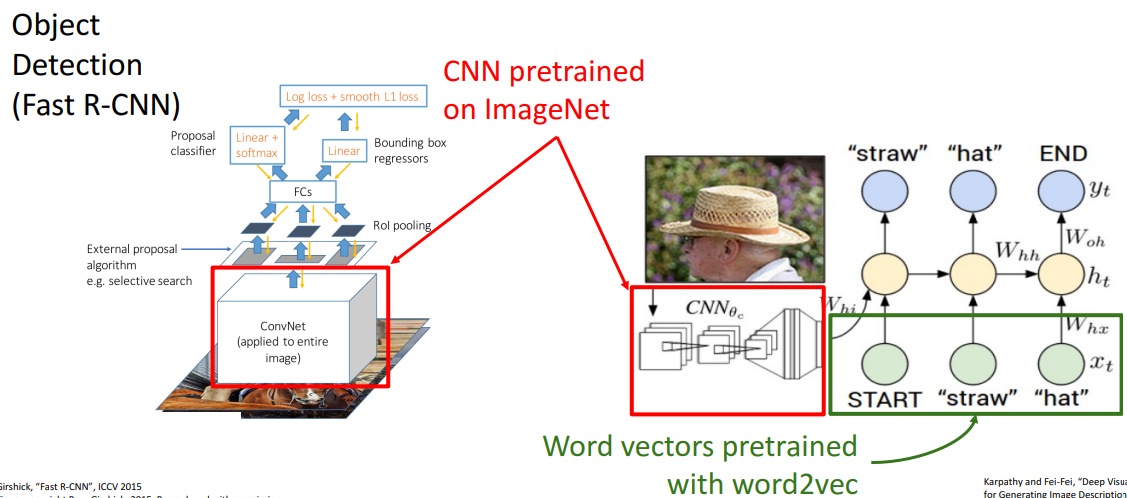
- 해석
- 둘 다 CNN으로 imageNet pretrain함 + fine tuning
b.
정리 중 . . ⚠ 🚧
'2023 딥러닝 > Michigan University DL' 카테고리의 다른 글
| [EECS 498-007 / 598-005] 13강: Attention (0) | 2024.02.27 |
|---|---|
| [EECS 498-007 / 598-005] 12강: Recurrent Neural Networks (0) | 2024.02.27 |
| [EECS 498-007 / 598-005] 10강: Training Neural Networks (Part1) (1) | 2024.02.27 |
| [EECS 498-007 / 598-005] 8강: CNN Architecture (1) | 2024.02.27 |
| [EECS 498-007 / 598-005] 7강: Convolutional Neural Network (0) | 2024.02.27 |