📌 본 내용은 Michigan University의 'Deep Learning for Computer Vision' 강의를 듣고 개인적으로 필기한 내용입니다. 내용에 오류나 피드백이 있으면 말씀해주시면 감사히 반영하겠습니다. (Stanford의 cs231n과 내용이 거의 유사하니 참고하시면 도움 되실 것 같습니다)📌
(📁 아래에 똑같이 제가 정리해놓은 블로그 참고..! 벨로그에 있는게 더 깔끔히 정리 잘되어있습니다)
https://velog.io/@ha_yoonji99/Michigan-DLcs231n-8%EA%B0%95-CNN-Architecture
[Michigan DL/cs231n] 8강: CNN Architecture
🔥Michigan University Deep Learning 8강🔥
velog.io
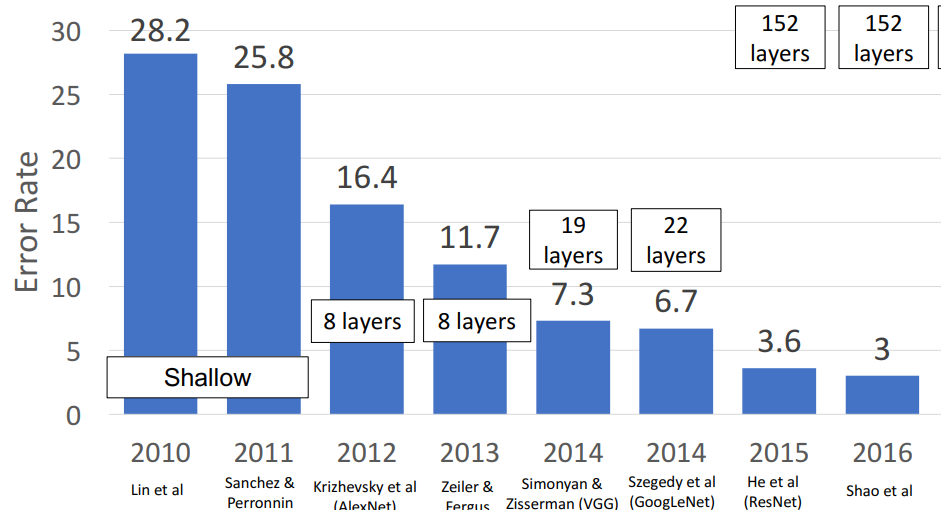
1. ImageNet classification Challenge
1) 개념
- 엄청 큰 규모 dataset
- 이미지 분류에 대한 큰 bench mark
- CNN설계에서 많은 시사점 남김
- 2010, 2011년 → Neural Network base X
- 2012년 → CNN이 첨으로 거대한 주류가 되던 해 (AlexNet이 압도함)
2. AlexNet
📍 계산구조 시사점: 초기 메모리多,파라미터수(fc layer)에서, 계산비용(conv에서 多)
1) 설계
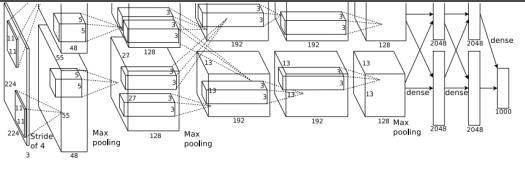
- 227 * 227 inputs
- 5 conv layers
- Max pooling
- 3 fully-connected layers
- relu 비선형 함수
2) 단점
- Local response normalization사용 (현재는 사용X, batch norm의 선구자)
- 2개의 GTX 580 GPU에 학습됨
- 각각 3GB 밖에 안됨 (현재는 12-18GB)
- GPU 메모리에 맞추기 위해 2개의 서로 다른 물리적 GTX카드로 분산됨
(GPU 여러개로 분할은 현대에서도 가끔 사용하지만 주로 사용X)
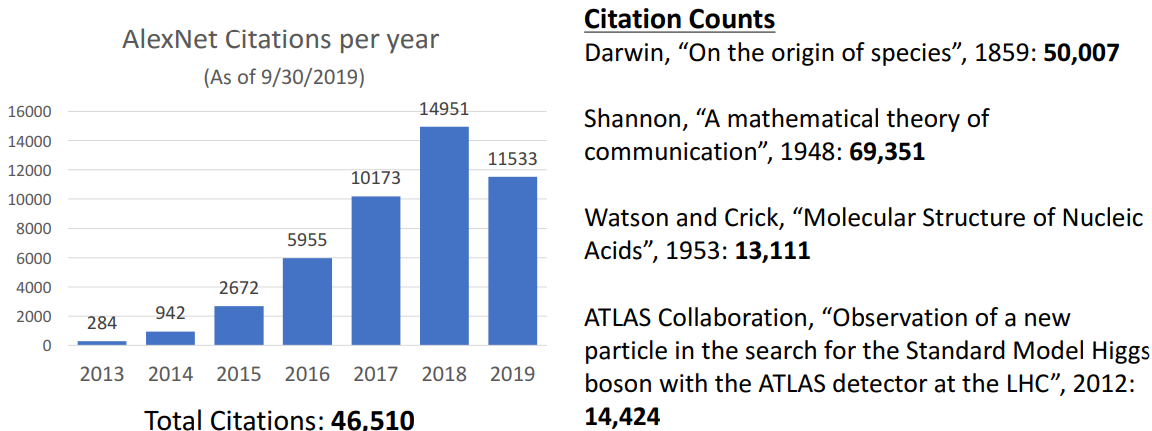
3) citations(인용횟수)
- 모든 과학분야에서 젤 인용 多
-
4) 계산 구조
a. Conv Layer

- C=3
: RGB - input size; H/W=227
: input size - filters=64
: output size의 channel과 같아야 됨 - output size; H/W=56
: ((W-K+2P)/S)+1
→ ((227-11+4)/4)+1 = 56 - memory(KB)=784
: (number of output elements) * (bytes per element) / 1024
→ (64(5656))*4/1024 = 784 - params(k) = 23 (학습가능 파라미터 수)
: number of weights
=(weight shape)+(bias shape)
= (CoutCink*k) + Cout
= (64311*11) + 64 = 23,296 - flop(M) = 73 (총 연산수 = 부동 소수점 연산수)
: Number of floating point operations(multipy+add)
= (number of output elements)*(1개의 output elem당 연산 수)
= (CoutH’W’) * (Cinkk)
= (645656) * (31111)
= 72,855,552
b. pooling layer

- Cin = Cout = 64
- output size; H/W = 27
: ((W-K+2P)/S)+1
= 27.5 (Alexnet은 항상 나눠떨어지지x)
= floor(27.5)=27 걍 내림함 - memory(KB) = 182
: (number of output elements) * (bytes per element) / 1024
= 182.25 - params(k) = 0
: pooling layer에는 learnable parameter 없음 - flop(M) = 0
: Number of floating point operations(multipy+add)
= (number of output positions)*(1개의 output position당 연산 수)
= (CoutH’W’) * (k*k)
= 0.4 MFlop
c. flatten
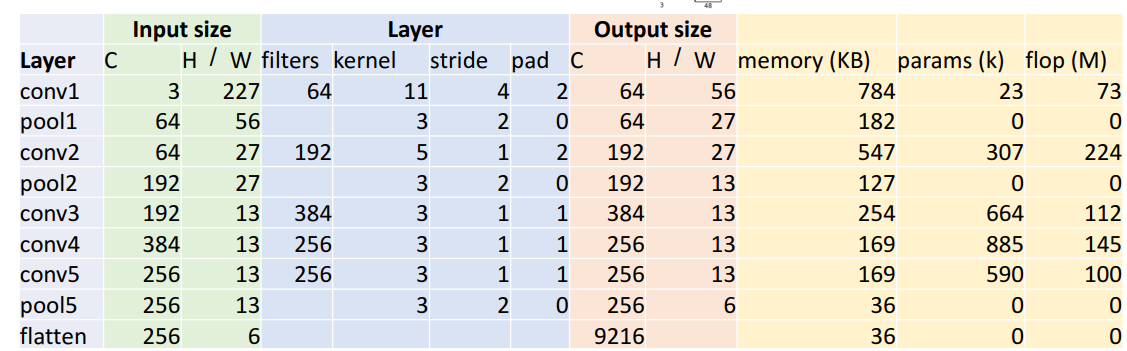
- flatten output size = 9216 (모든 공간구조 파괴, 벡터로 평면화)
: Cin * H * W
=25666 = 9216
d. FC
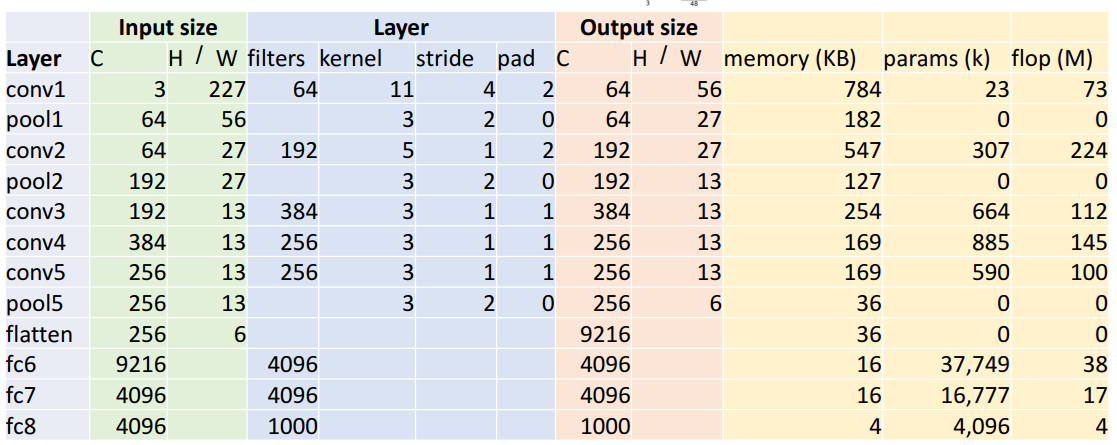
- FC params
: Cin * Cout + Cout
= 9216 * 4096 + 4096
= 37,725,832 - FC flops
: Cin * Cout
= 9216 * 4096
= 37,748,736
5) 위 계산에서 알 수 있는 특징
- 시행착오적
- 지금은 사용 적음
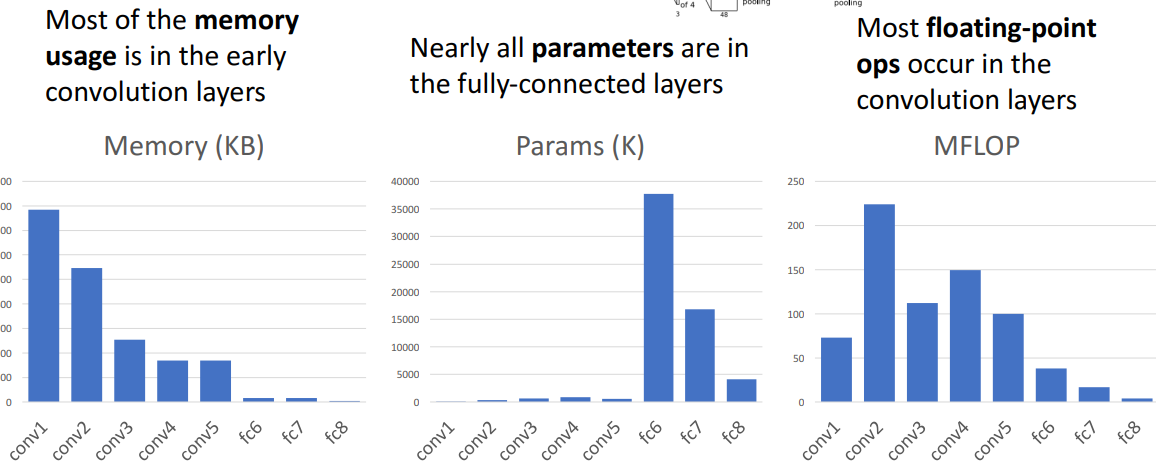
a. Memory 사용량
- 초기에 메모리 多
- 이유) 초기 conv layer의 output이 상대적으로 높은 공간 해상도와 많은 수의 filter가져서
b. parameter 수
- 모든 파라미터들은 fc layer에 존재
- 이유) 66256의 tensor 가지고 있고, 4096의 숨겨진 차원으로 완전히 연결되어 있어서
- Alexnet의 모든 learnable parameter가 fully connected layer에서 나옴
- 이유) 66256의 tensor 가지고 있고, 4096의 숨겨진 차원으로 완전히 연결되어 있어서
c. 계산 비용
- conv layer에서 연산량 多
- 이유) 계산 비용은 fc에서는 별로 안큼.(걍 곱하기만 해서)
반면 conv layer에는 filter수가 많고, 높은 공간 해상도면 계산비용 ↑
- 이유) 계산 비용은 fc에서는 별로 안큼.(걍 곱하기만 해서)
3. ZFNet: Bigger AlexNet
📍 계산구조 시사점: 더 큰 네트워크가 더 성능 good
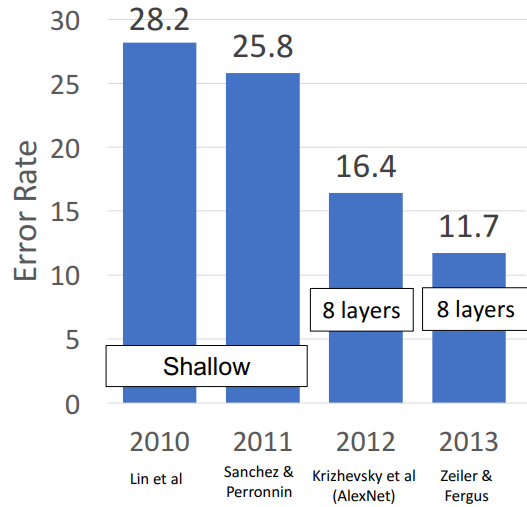
1) 특징
- more trial, less error
2) AlexNet과 바뀐 점
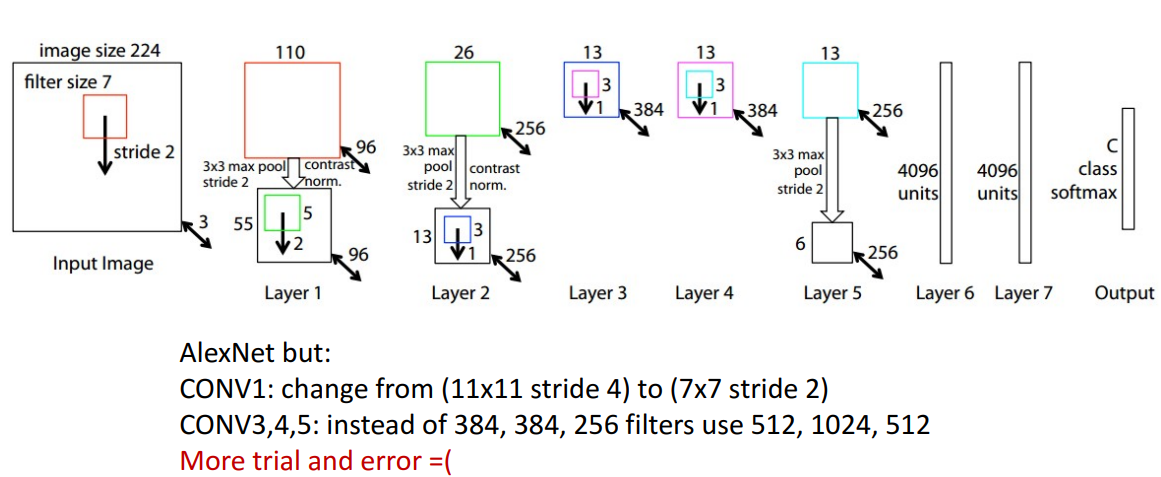
- conv1
- (11x11 stride 4) → (7x7 stride 2)로 바뀜
- 기존 4만큼 down sample → 2만큼 down sample로 바뀜
- 높은 공간 해상도 & 더 많은 receptive field & 더 많은 컴퓨팅 비용
- (11x11 stride 4) → (7x7 stride 2)로 바뀜
- conv3,4,5
- (384,384,256 filters) → (512,1024,512)로 바뀜
- filter 크게 = 네트워크 더 크게
- (384,384,256 filters) → (512,1024,512)로 바뀜
=⇒ 결론) 더 큰 네트워크가 더 성능이 좋다
4. VGG: Deeper Networks, Regular Design
📍 계산구조 시사점: 굳이 큰 필터 필요X, conv layer개수 더 중요, 채널 수 많아져도 계산비용 동일 - Stage 사용
1) AlexNet, ZFNet 공통 문제점
- ad hoc way (네트워크 확장, 축소 어려움)
- hand design 맞춤형 convolution architecture
⇒ VGG는 네트워크의 동일한 조건으로 전체 적용 (단순화함)
2) VGG 설계 규칙 (정확한 구성에 대해 생각X)
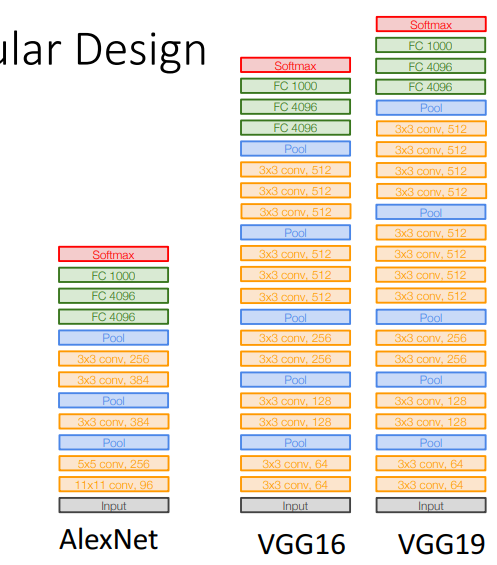
- 기본 세팅
- All conv are 3x3 stride 1 pad 1
- All max pool are 2x2 stride 2
- After pool, double channels
- stage
- Alexnet은 5개의 conv layer있었고, VGG는 더 깊게 한것
- 1개의 stage = conv, pooling layer등 포함
- VGG: 5개의 stage
-

3) 특정 설계 규칙 채택 이유
a. conv layer

- 기존: learnable parameter여서 매번 달라짐
- → conv = 3x3 으로 고정시킨 것
- 증명
- 가정1: 1개의 conv layer + 5x5 kernel size 일때,
-
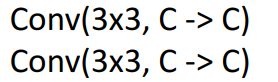
⇒ 굳이 큰 필터 필요X → hyperparameter로 kernel size 신경 필요X → conv layer수만 신경
b. pooling layer

- 해석
- pool 할때마다 채널 수 2배로
- 증명
- stage 1
-

4) AlexNet vs VGG-16
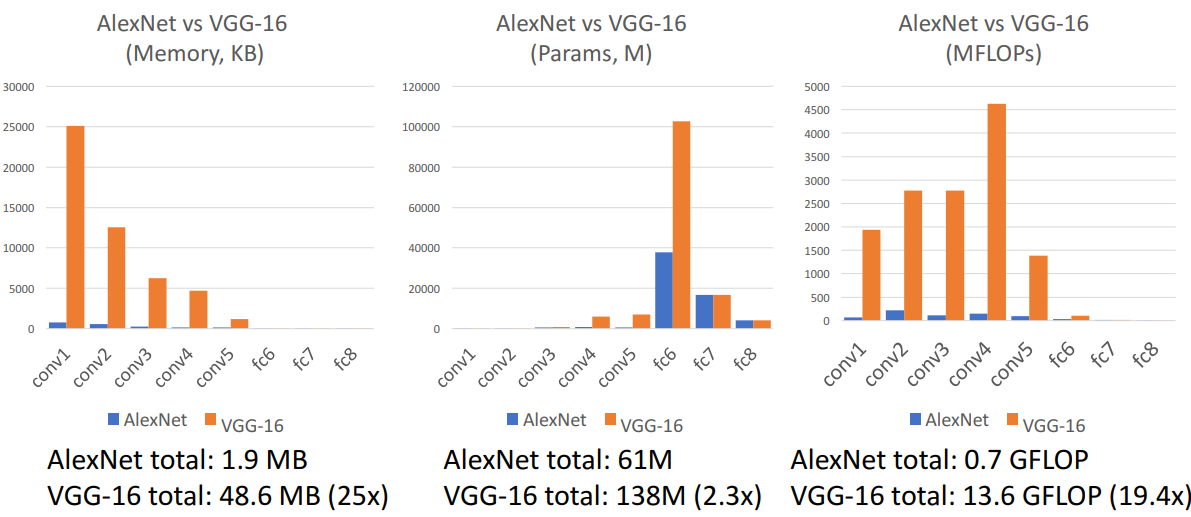
⇒ 결론) 네트워크 ↑ → 성능 ↑
5) 질문
Q. VGG도 multiple GPU사용?
A. multiple GPU있었지만, 데이터 병렬처리로 배치분할 & 배치별로 다른 GPU에서 계산
→ 모델 분할 X, 미니배치 분할O
5. GoogLeNet: Focus on Efficiency
📍 Stem, Inception Module, Global Average pooling, Auxiliary Classifier
- 기존) network커지면 : 성능 더 좋음
1) 개념
- 효율성에 초점 ⇒ 전체적인 복잡성 최소화
2) Stem network
- 개념
- input image를 엄청나게 down sampling함 (경량의 stem 이용)
- 몇개의 layer만으로 매우 빠르게 down sampling가능
- 값비싼 convolution 수행필요X
- 구조
-
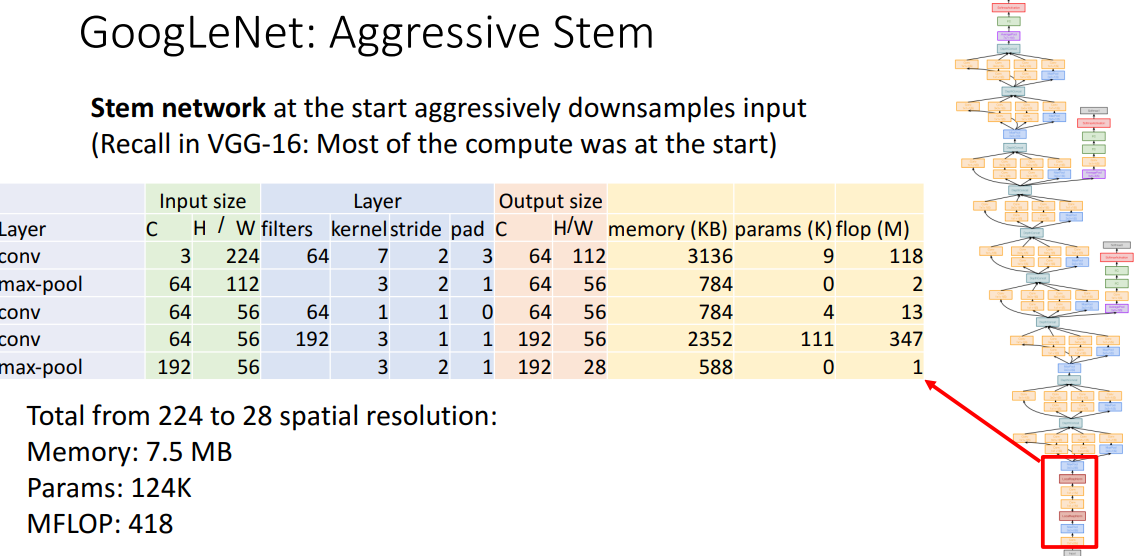
- VGG와의 비교
-

- VGG가 GoogleNet보다 18배 더 비쌈3) Inception Module
- 개념
- 전체 네트워크에서 반복되는 로컬 구조
- 기존의 conv-conv-pool의 구조처럼, GoogleNet은 작은 inception module design해서 전체 네트워크에서 반복
- 구조
-
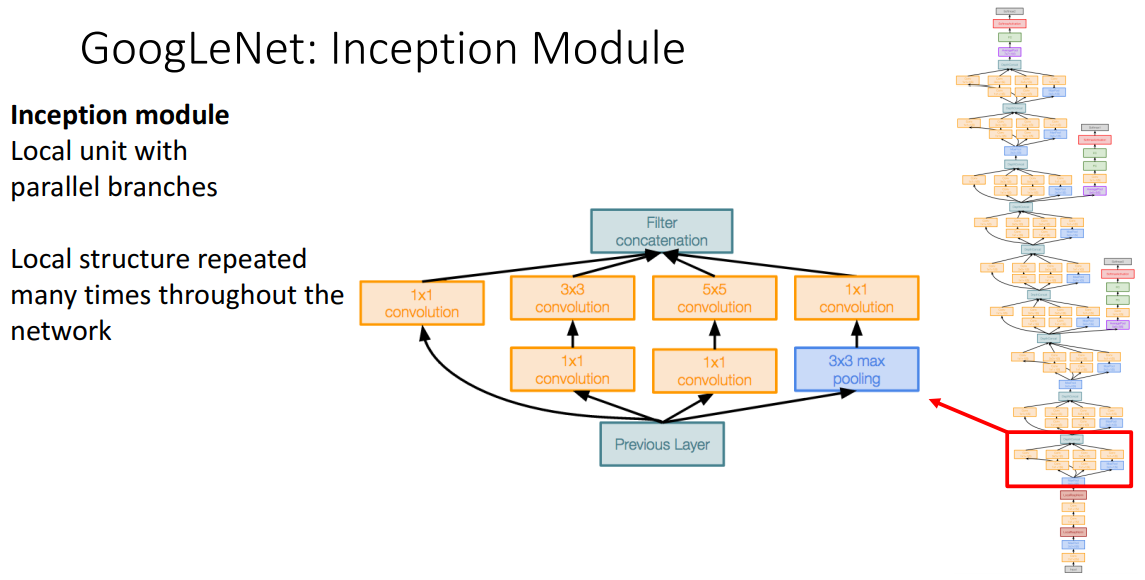
- 3x3 max pooling stride 1- 기능
- 기능1
- 기존의 kernel size를 대신하여 3x3 stack으로 대체할 수 있단것
- hyper parameter로 kernel size제거 (항상 모든 kernel size 수행할 것이므로)
- 기능2
- 더 비싼 conv (3x3…) 사용전에 1x1 conv사용하여, 채널 수 줄임 (bottleneck현상 활용)
- 기능1
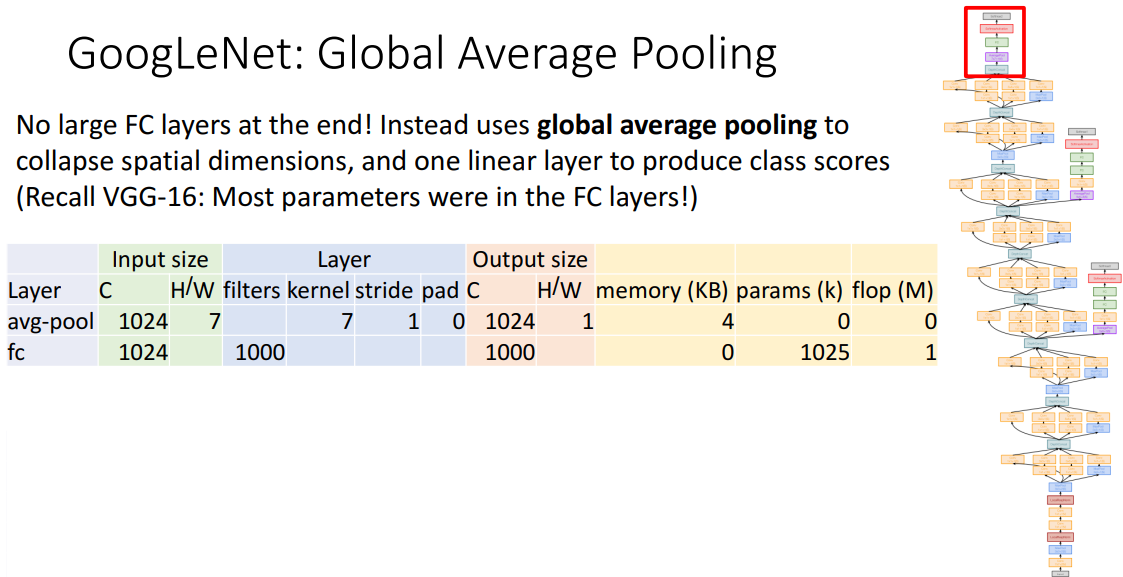
4) Global Average Pooling
- 개념
- 파라미터를 줄여야하므로
- 평탄화하여 공간정도 파괴하기보다, 전체에 대한 average pooling으로 공간 차원 축소한 뒤 FC Layer 한번 사용
- 구조
-
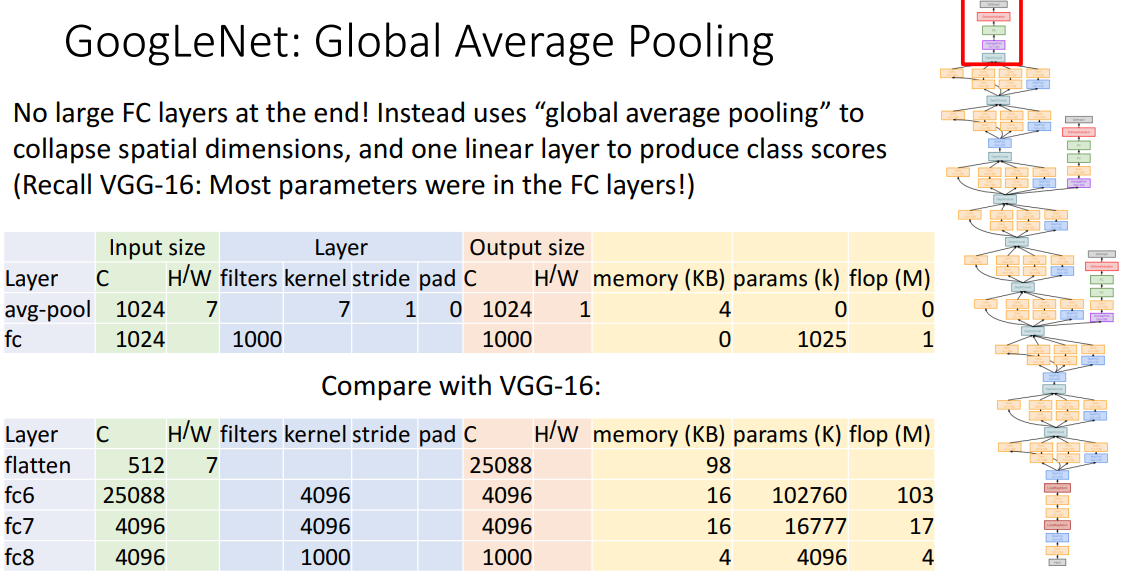
- VGG와 비교
-
5) Auxiliary Classifiers (보조 분류기)
- 개념
- Batch norm 발생전에 생김
- 10개 이상 layer가 있을때 train하기 어려웠음
- 10개 이상 layer train 위해서 ugly hacks에 의존해야 했음
- Network 깊이가 깊을때, 중간 layer의 학습 돕기 위해 설계
- 최종적으로 맨 끝, 중간 이 2개 각각에서 점수 받음
- gradient 계산해서 backprop하여 gradient 전파 (당시 심층 네트워크 수렴시키기 위한 trick)
- 추가적인 보조 분류기 출력 (gradient)를 앞 계층에 넣고, 중간 계층에도 이게 도움되며, 이것들의 일부에 기반해서 분류할 수 있어야 됨
- Batch norm 발생전에 생김
6. Residual Networks
📍 batch norm 발견이후/지름길/VGG(Stage) + GoogLeNet(Stem, Inception Module, Global Average pooling) 사용
1) 모델 생성 배경
- 문제점
- Batch Norm발견 후, 기존에는 bigger layer이 더 성능 좋았는데 이제 깊은 모델이 성능 더 안좋아짐 !
= layer가 깊어질수록 효율적인 최적화 불가능 !
- Batch Norm발견 후, 기존에는 bigger layer이 더 성능 좋았는데 이제 깊은 모델이 성능 더 안좋아짐 !
- 문제에 대한 이유 예상
- 깊은 모델이 overfitting 된 거다.
- 기본 가정
- deeper model은 shallower model을 모방할 수 있다
ex. 56 layer가 20 layer를 모방한다(20 layer의 모든 layer를 56 layer에 copy한다고 생각)
→ 따라서 deeper model은 최소한 shallow model보다 더 성능이 좋다 - ⇒ 발생하는 문제점이 기본 가정에서 벗어남*
- deeper model은 shallower model을 모방할 수 있다
- 해결책
- layer가 깊은 경우, identity function을 더 쉽게 학습할 수 있도록 network 변경해야됨
- 그렇게 해서 나오게 된게 Residual Network
결론) layer가 깊어질수록 효율적인 최적화 불가능 → layer가 깊을때 identity function을 더 쉽게 학습하도록
2) Shortcut
- 개념
-
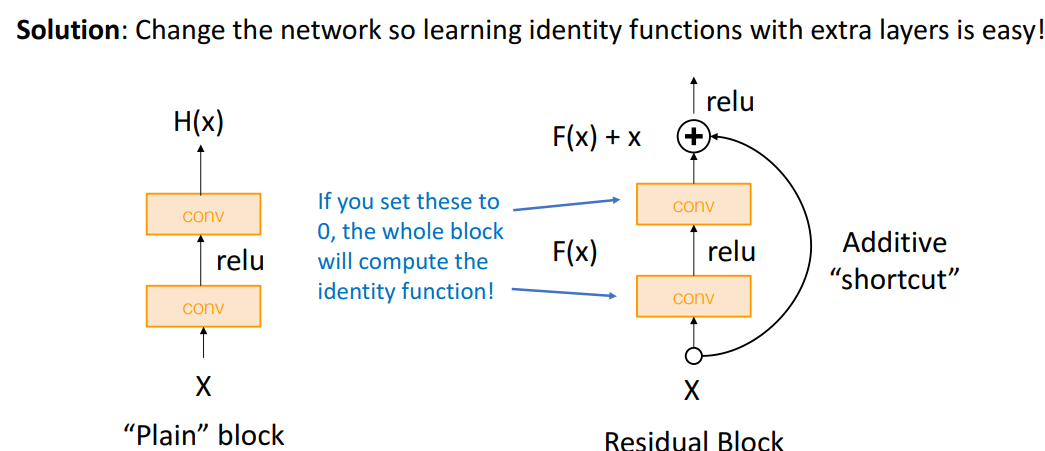
- 지름길 생성- 장점
- identity function을 매우 쉽게 배울 수 있음
- 지름길 사이의 block들을 가중치=0으로 block identity 계산 가능
= deep network가 emulate(모방)하기 쉽게 만듦
- 지름길 사이의 block들을 가중치=0으로 block identity 계산 가능
- gradient 전파를 개선하는데 도움
- ex. 역전파의 +일때, 기울기를 입력에 모두 복사. 이 residual block을 통해 역전파시 지름길로 복사해줄 수 있음
- identity function을 매우 쉽게 배울 수 있음
3) 모델 구조
- 개념
- VGG(단순한 설계 원칙)와 GoogleNet(수학적 계산)의 가장 좋은 부분에서 영감 받음
- 많은 residual block의 stack임
- a. VGG에서 따온 것*
-
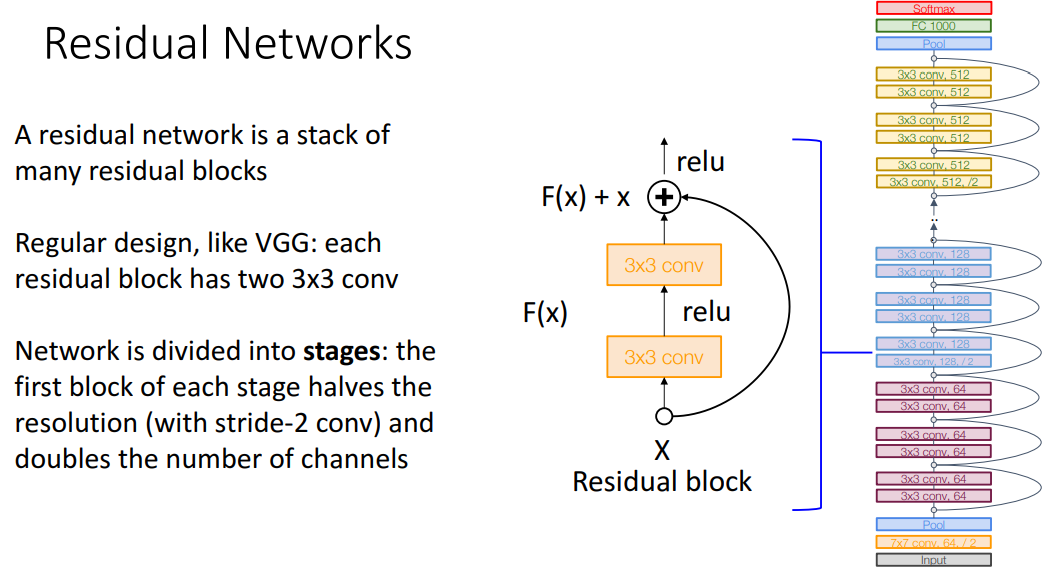
- 각 residual block은 2개의 3x3 conv 있음
- Stage 구조
- 각 stage의 첫번째 block은 stride 2 conv로 해상도 반으로 줄임
- 채널 2배로 늘림
b. GoogleNet에서 따온 것
- Stem 구조
- 처음 input을 down sampling함
- Global Average Pooling
- 그대로 fully connected layer로 안넘김
- 파라미터 줄이기 위함
c. 사용자가 정해야할 것
- 초기 네트워크 너비 ex. C=64
- stage당 block 수 ex. 3 residual blocks per stage4) 모델 예시
a. ResNet-18

b. ResNet-34

- 해석
- 매우 낮은 error 달성
- VGG-16과 비교
-

- 둘다 resnet이 더 좋음
- GFLOP: ResNet은 앞에 downsampling하고 시작해서 차이 많이 남5) Bottleneck Block (GoogleNet의 Inception Module)
- 개념
- 더 깊어짐에 따라 Block design수정
- Basic Block
-
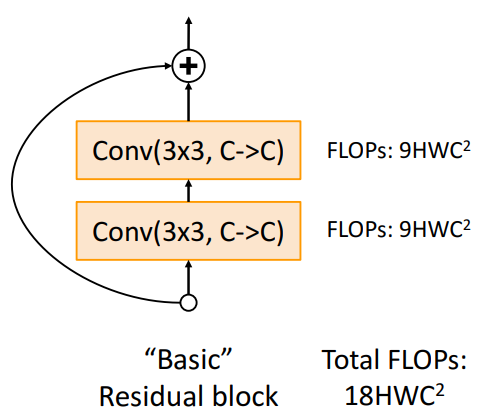
- 각 conv layer에서만 계산 됨- Bottleneck Block
-
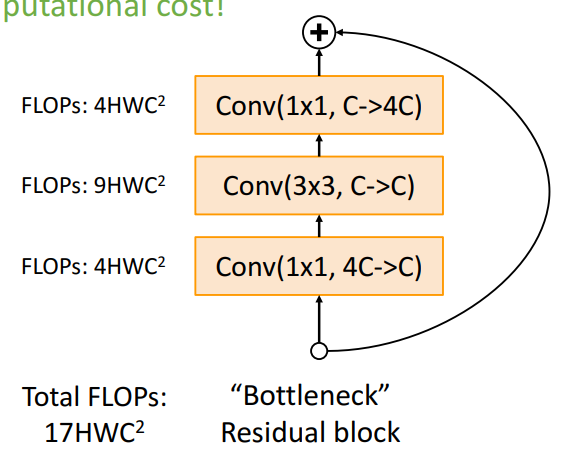
- 4배 많은 channel의 입력 수락
⇒ 결론) 계산 비용 증가시키지 않으면서, 더 깊은 네트워크 구축 가능6) 최종 전체 모델 구조
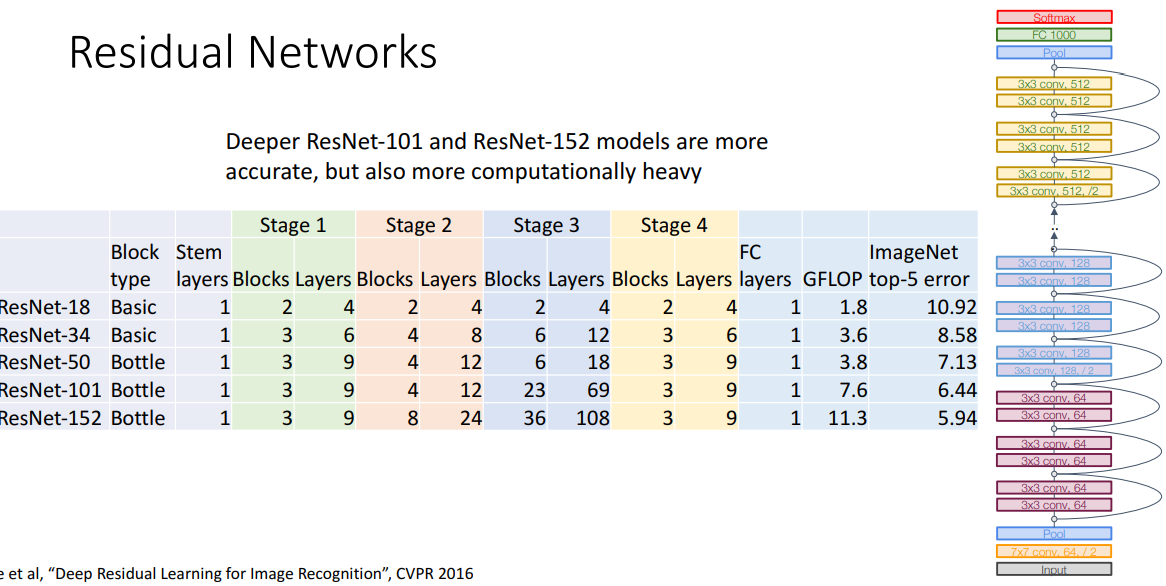
- 개념
- 깊게 쌓을수록, 더 error 줄어듦 !!
- 결과
- 다 이겼음
-

7. Improving Residual Networks: Block Design
📍 Conv 전에 Batch norm과 Relu넣기
- 개념
- Conv 전에 Batch norm과 Relu를 넣어서 성능 개선가능

8. Compare Complexity
- 전체 비교
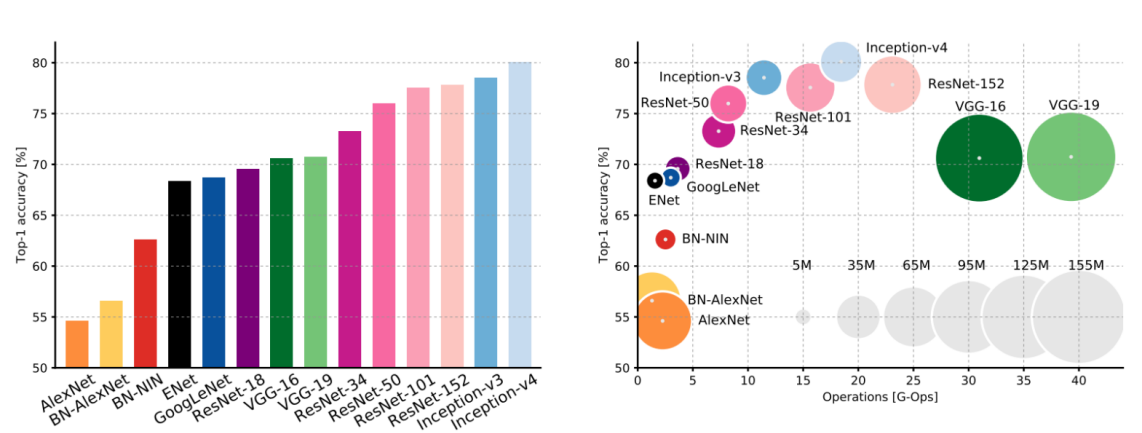
- 해석
- size of dot: 학습 파라미터 수
- G-Ops(Operations): 해당 아키텍처의 여유경로 계산하는데 걸리는 FLOP수
- Inception-v4: Resnet + Inception
- VGG: 가장 높은 메모리, 가장 많은 연산량 (매우 비효율)
- GoogLeNet: 매우 효율적 연산량, 그치만 성능은 그닥..
- AlexNet: 매우 적은 연산량, 그치만 엄청 많은 파라미터 수
- ResNet: 심플 디자인, 더 나은 효율성, 높은 accuracy (더 깊게 설계함에 따라)
9. Model Ensembles
- 2016 우승자: 좋은 모델들끼리 앙상블함
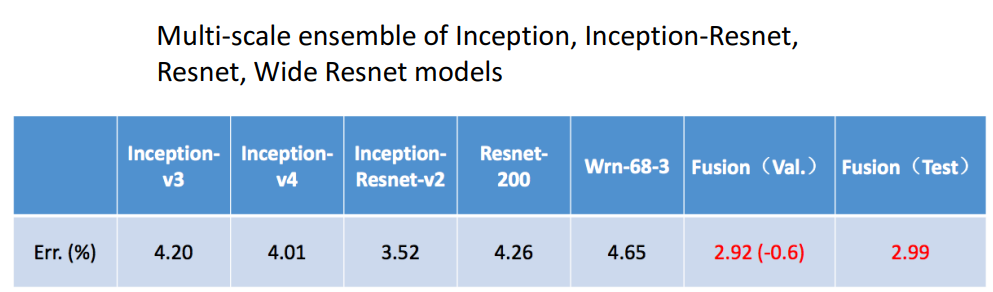
10. ResNeXt
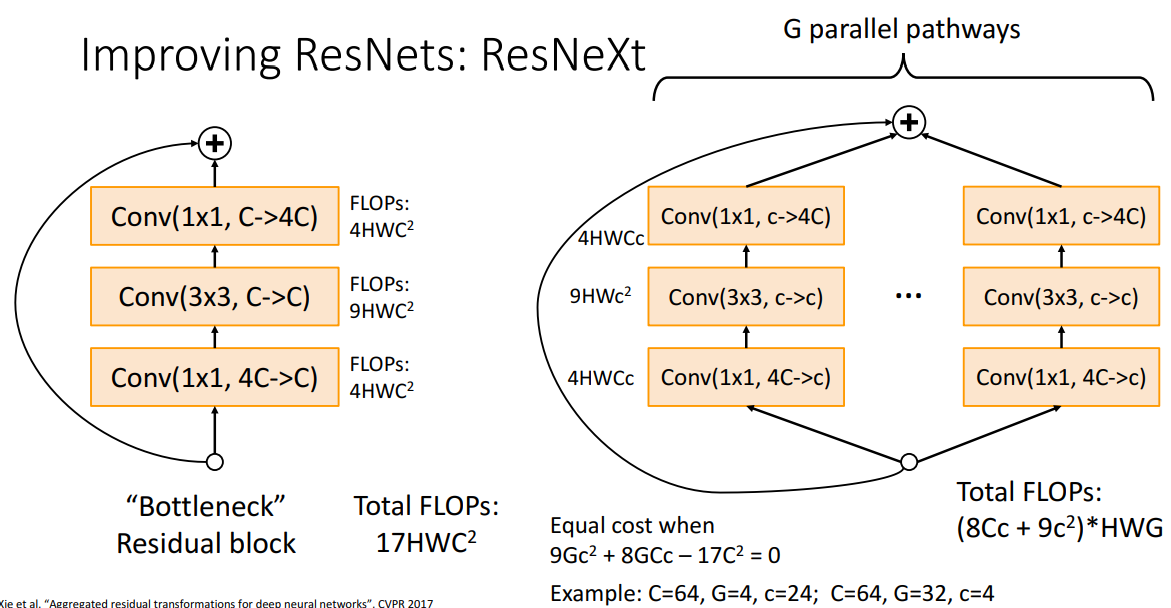
📍 ResNet 개선 버전 - Group 추가
- 개념
- 하나의 bottleneck이 좋으면, 이를 병렬적으로 구성하면 더 좋지 않겠는가!
-
- 계산 결과
- Total FLOPs: (8Cc+9c^2)HWG
- 이걸로 패턴 도출 가능
- C=64,G=4,c=24 ; C=64,G=32,c=4 일때 위와 같은 결과 도출 가능
- ⇒ 결론) Group 으로 병렬적으로 할때 더 좋은 성능 보임*
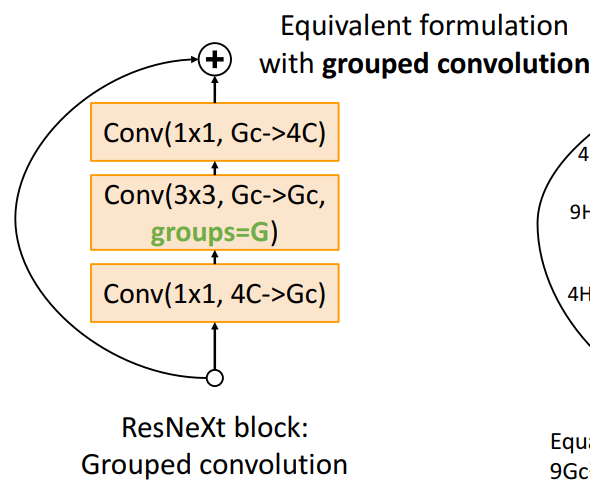
1) Grouped Convolution
- 구조
- group=1일때
-

2) ResNeXt에 Group 추가
- 구조
-
3) Group별 성능 결과
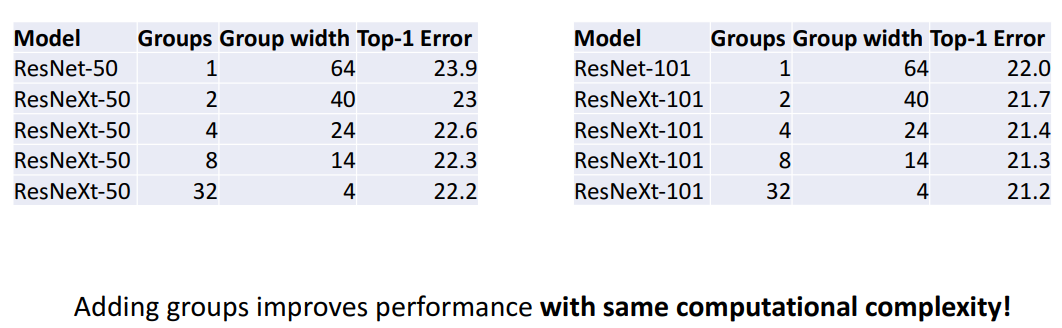
- 해석
- Group을 추가함에 따라 성능 더 좋아짐!
11. SENet
(Squeeze and Excite)
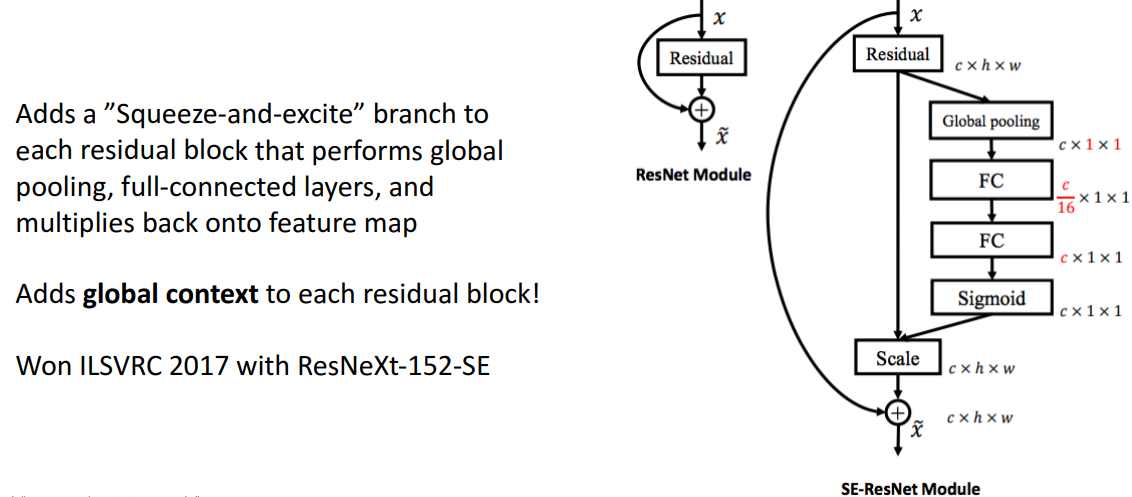
- 개념
- Residual block 사이에 Global pooling, FC, Sigmoid 넣어서 Global context 만듦
'2023 딥러닝 > Michigan University DL' 카테고리의 다른 글
| [EECS 498-007 / 598-005] 11강: Training Neural Networks (Part2) (2) | 2024.02.27 |
|---|---|
| [EECS 498-007 / 598-005] 10강: Training Neural Networks (Part1) (1) | 2024.02.27 |
| [EECS 498-007 / 598-005] 7강: Convolutional Neural Network (0) | 2024.02.27 |
| [EECS 498-007 / 598-005] 6강: Backpropagation (0) | 2024.02.27 |
| [EECS 498-007 / 598-005] 5강: Neural Network (0) | 2024.02.27 |