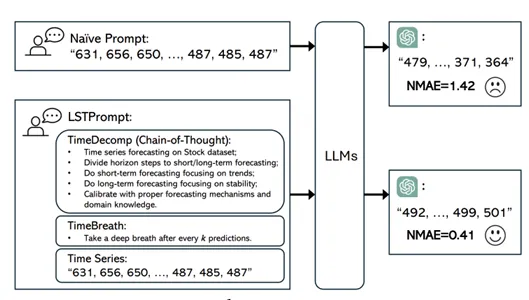
Motivation기존 시계열 예측 모델은 도메인별 전용 학습에 의존해 데이터 간 공통 패턴을 활용하지 못함.도메인 간 데이터 특성 다양성, 혼동 문제, 학습 속도 불균형으로 인해 통합 모델 학습이 어려움.도메인 간 공통 패턴 학습 및 전이를 가능하게 하는 통합적이고 일반화 가능한 모델 필요. Contribution최초의 크로스-도메인 통합 시계열 모델 UniTime 제안자연어 기반 도메인 지침으로 도메인 혼동 해결.마스킹 기법으로 도메인 간 학습 속도 불균형 완화.언어와 시계열 데이터의 통합 학습 구조 설계Language-TS Transformer로 도메인 식별 및 데이터 일반화 구현. Proposed Method Time Series Tokenizer역할: 시계열 데이터를 전처리하여 모델에 입력할 ..