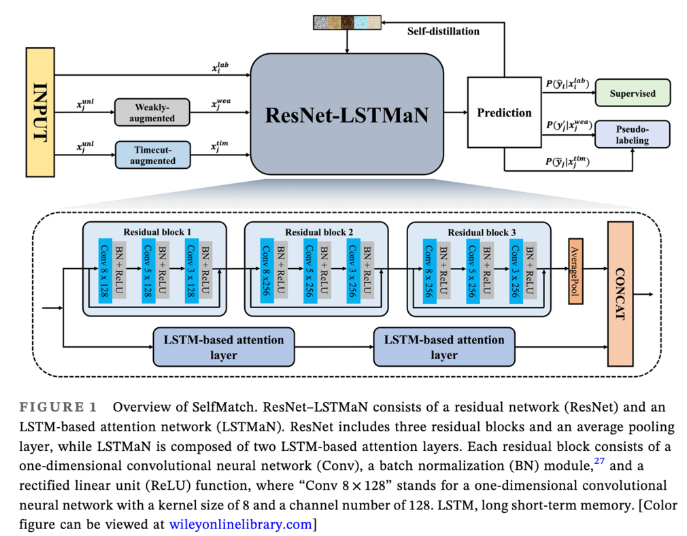
Abstract SCVAE 시계열 이상탐지위함 압축된 컨볼루션 VAE UCI dataset의 레이블이 붙은 시계열 데이터에 적용됨 SqueezeNet의 Fire모듈을 적용하기 전후의 모델 비교 Introduction 제조 공정에서는 불량과 고장에 대한 레이블이 없음 ⇒ 예측 정비에 앞서 공정의 행동 패턴에 대한 진단이 필요 레이블이 없을때) 비정상적인 행동 패턴을 이상 현상으로 가정 (센서 데이터가 시계열이기 때문에 시계열 데이터의 특성을 반영하는 모델을 찾는 것이 중요) 기존 연구된 모델들 비지도 이상 탐지를 위한 컨볼루션 신경망(CNN) 기반 변이형 오토인코더(VAE) 모델 기존) 클라우드 기반 접근방식 → 현재) 엣지기반 접근방식 일부 컴퓨팅 부하를 에지 장치로 옮겨 실시간 추론을 가능 데이터 통신..