Abstract
Domain Adaptation 이란, transfer the knowledge learned from a labeled source domain to an unlabeled target domain whose data distributions are different.
source domain 에서의 학습 데이터는 real-world 에서는, 보안문제로 사용불가능한 경우가 자주있다. 그래서 Source-Free Domain Adaptation (SFDA) 방법이 주목받고 있음. 이름 그대로 source data 를 이용하지 않고 domain adaptation을 수행하는…
논문에서 제안하는 방법은 SFDA-DE : source Distribution Estimation 을 이용하여 직접적으로 source data 활용하지 않고 Domain Adaptation를 수행하는 방법.
- Spherical k-means clustering을 통해서 target data 의 수도라벨을 만들어줌. (Spherical k-means란, 유클리디안 대신 코사인 디스턴스를 활용한 k-means)
- 초기 class centers는 pre-trained model 의 classifier로부터 학습된 가중치 벡터(앵커)로 지정됨
- 타겟 데이터와 앵커를 활용해서, source domain의 class-conditioned feature distribution 을 추정함
- 추정된 분포로 부터 surrogate features 를 추출한 뒤, contrastive adaptation loss 를 최소화함으로서 두개의 domain 을 align 하는데 이용된다.
Introduction
source domain 과 target domain 의 분포 불일치, 라벨링 된 source 데이터 부족등으로 인한 CNN 의 한계.
그로인해 DA가 주목받았고, DA 는 annotated (labeled) 로 부터 학습된 지식을 target domain 으로 transfer 시켜줌 (일반적으로 두 개의 서로 다른 데이터 분포를 두 도메인에서 공유되는 상호 특징 공간에 동시에 매핑하는 방식으로 모델 전이성을 달성)
그러나 traditional DA 는 source data 를 보안상 이슈로 활용 불가능한, 최근의 많은 상황에서 적용하기 어려운 부분이 있음.
그래서, SFDA (즉 source data 없이 target data 와 source domain 으로부터 pre-trained된 모델만 이용하여 cross-domain knowledge transfer를) 하는 연구가 주목받아옴. 그러나, SFDA와 관련된 선행연구들은 명시적으로 source-target domain 간의 분포를 얼라인하는 과정이 없었다.
본 연구에서는 SFDA 를 통한 이미지 분류에 중점을 둠
- source data(영어 음성 데이터)에 접근하지 않고 source distribution(영어 발음과 억양 분포) 을 추정함
- source data 로 사전학습된 모델로 부터 추출된 domain information(영어 발음과 억양 구분하는데 어떤 특징이 중요한지) 을 이용하고, source classifier로부터 학습된 weight를 class anchor(각 발음과 억양 나타냄)로 사용
- 이러한 anchors들은 각 class의 피쳐 중심점을 초기화하는데 사용됨, 그리고 spherical k-means가 target features를 clustering 하기위해 적용되고, 이는 target data에 강건한 수도 라벨을 제공한다.
- 또한, target data의 semantic statistics와 해당 anchor를 활용하여 소스 도메인의 특징 분포를 class-wisely하게 추정하는데, 이를 SDE(source distribution estimation)(영어 음성데이터의 발음과 억양분포 예측)이라고 한다.
- 마지막으로, SDE 로 부터 추정한 분포로 부터 surrogate features(목표 도메인의 음성 데이터의 발음과 억양)를 추출 (real but unknown 인 source features) 하여 target features(한국어 음성데이터)와 얼라인함. by minimizing contrastive domain adaptation function
Method
제안 방법론을 요약하면
- source anchor 와 spherical k-means를 통해 target data에 pseudo-label을 부여함
- source domain 의 class-conditioned distribution을 추정함 (SDE)
- 추정된 분포로 부터 surrogate feature를 추출하고, 이를 이용하여 source-target 도메인을 align함 (by minimizing contrastive adaptation loss function)
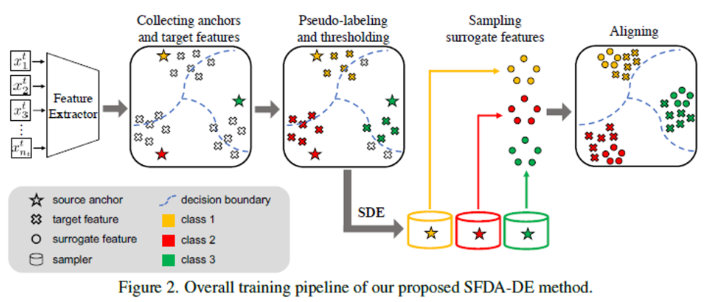
- Pseudo-labeling w anchors
- 해당 step에서는 unlabeled target data의 class를 source domain class center와 비교해 pseudo-label을 할당한다. SFDA setting에서는 target data와 source pretrained model만 활용이 가능하다. 따라서, data가 feature extractor를 통과한 후 feature space 상에서 source anchor에 가까운 cluster를 기반으로 pseudo label을 할당한다.
- Source distribution Estimation
- Traditional DA에서는 source와 target domain의 distribution을 일치시키는 것을 목표로 한다. 그러나, SFDA setting에서는 source data를 활용할 수 없기 때문에 실질적으로 두 domain 간의 distribution을 일치시키는 것은 제한적이다. 선행연구들의 경우 pretrained model을 활용해 간접적으로 문제를 해결해 왔기 때문에 사실상 sub-optimal solution을 도출하는것으로 해석할 수 있다. 논문에서는 pretrained model로부터 source feature distribution을 explicit하게 추정하는 SDE를 제안한다.
- Source-free domain adaption
- SDE를 통해 source domain의 feature distribution을 추정했기 때문에 sampling을 통해 surrogate feature를 생성하면 traditional DA와 문제상황이 동일해진다. 해당 feature에 대해 Contrastive Domain Discrepancy (CDD)를 통해 source distribtion과 target distribution을 align한다.

CDD loss는 다음과 같다.

Experiments
