Abstract
- SelfMatch (이 논문에서 제시한 모델 !!)
- 목적: 시계열 분류 (TSC)
- TSC를 위한 특징 추출기인 ResNet–LSTMaN을 설계하여 특징 및 관계 추출을 담당
- 방법: supervised + unsupervised + self distillation
- unsupervised: (pseudo labeling 적용) label data에 대한 feature extract (레이블이 지정된 데이터와 지정되지 않은 데이터 간의 연결을 탐색)
- 약하게 증가된 시퀀스는 같은 시퀀스의 Timecut-증가된 버전의 예측을 안내하는 목표
- (= 어떤 데이터 시퀀스의 변화를 이해하고 이를 기반으로 미래의 변화를 예측)
- self distillation: 높은 수준에서 낮은 수준으로의 지식흐름 → 낮은 수준의 semantic information extract
- 목적: 시계열 분류 (TSC)
1. Introduction
- 대표적인 TSC 방법
더보기
데이터의 내부 representation layer를 펼쳐 representation 간의 본질적인 연결을 포착하는 것
- 예시
- 완전 컨볼루션 네트워크(FCN), 멀티프로세스 캡슐 네트워크(TSCaps), 강인한 시간 특징 네트워크(RTFN)
- Semi supervised learning의 유행
- : 소량의 레이블이 지정된 데이터와 대량의 레이블이 지정되지 않은 데이터를 결합
- TSC를 위한 SSL에 대한 연구들
- Chen 등은 레이블이 지정된 데이터와 지정되지 않은 데이터 간의 차이를 측정하기 위해 동적 시간 왜곡(DTW)을 기반으로 한 메타-특징 기반 거리인 DTW-D를 도입했습니다.
- Marussy와 Buza는 DTW와 계층적 클러스터링을 기반으로 한 준지도 시계열 접근 방식인 SUCCESS를 제안했습니다.
- Xu와 Funaya는 시계열 데이터의 기본 구조에 초점을 맞춘 그래프 기반 SSL 알고리즘을 사용했습니다.
- Wang 등은 심전도(ECG) 데이터의 고급 구조적 정보를 포착하기 위해 슬라이딩 윈도우와 서포트 벡터 머신(SVM) 앙상블을 통한 단어 가방 접근 방식을 제시했습니다. 최소 설명 길이 기반 SSL은 정확한 준지도 시계열 분류기를 생성하기 위해 개발되었습니다.
- González 등은 자기 레이블링 기술을 SSL에 통합하여 35개의 UCR 데이터 세트에서 괜찮은 성능을 달성했습니다.
- Wang 등은 레이블이 지정된 데이터와 지정되지 않은 데이터 간의 연결을 탐색하기 위해 셰이플릿 방법과 의사 레이블링 기술을 적용했습니다.
- Jawed 등은 분류 및 예측 작업을 위한 자기 감독 다중 작업 학습 알고리즘을 제안했습니다
⇒ 위의 SSL 알고리즘들은 다음 중 하나 또는 두 가지 방법을 특징으로 삼음(label이 없는 data다룰때 유용)
- 엔트로피 최소화: 모델의 예측 신뢰도 증가.
- 일관성 정규화: 입력이 변경될 때 동일한 출력 분포를 생성.
- 유사 레이블링(self supervised이라고도 함): 모델의 클래스 예측을 레이블로 사용하여 학습.
- 일반 정규화(예: 데이터 증강): 모델이 훈련 데이터를 잘 일반화하고 과적합을 피하는 데 도움.
⇒ but ! TSC를 위한 Semi Supervised L 알고리즘은 얘네를 조합하는 데에 큰 관심x
- 이미지 분류에서의 위 방법들 결합한 알고리즘 등장
- Berthelot 등은 엔트로피 최소화, 일관성 정규화, 일반 정규화를 통합하는 단일 손실을 사용하는 Semi Supervised L 알고리즘인 MixMatch를 소개했습니다.
- MixMatch의 기반 위에, ReMixMatch는 분배 정렬과 증강 앵커링 기술을 Semi SL 프레임워크에 통합했습니다. 분배 정렬은 모델의 집계된 클래스 예측의 분포를 실제 클래스 레이블의 마진 분포와 일치시키는 데 사용됩니다. 반면에 증강 앵커링은 일관성 정규화 방법의 업그레이드 버전입니다.
- Sohn 등은 ReMixMatch와 유사 레이블링을 결합한 FixMatch를 제안하여 레이블이 있는 데이터의 관계를 포착
- Semi supervised learning 한계점
- ⇒ 제기된 의문점: 높은 수준에서 포착된 풍부하고 정교한 의미 정보가 낮은 수준에서 거친 의미 정보를 추출하는 데 사용될 수 있는가?
- ⇒ 높은 수준에서 얻은 의미 정보를 사용하여 낮은 수준의 의미 정보 추출을 안내하는 것이 가능하며, 이는 높은 수준에서 추출된 높은 수준의 의미 정보의 질을 향상시키는 데 유익합니다. 그러나 이 문제는 대부분의 기존 준감독 딥러닝 알고리즘에서 잘 연구되지 않았습니다.
더보기
- 이미지 분류 & TSC에서 모두 self representation 부족
- SSL 알고리즘의 성능은 어느 정도 높은 수준에서 추출된 풍부한 의미 정보의 질에 달려 있으며, 이는 낮은 수준에서 얻은 거친 의미 정보의 질에 기반합니다. 다시 말해, 낮은 수준에서 추출된 의미 정보는 높은 수준에서 의미 정보를 추출하는 데 중요
- (= representation layer는 low 수준에서 거칠고 부족한 정보 수집 high수준에서는 풍부하고 정교한 정보 수집)
- 위 한계에 대한 보완점
- 자기 학습(Self-distillation, SD)
- 동시에 선생님과 학생으로서, 높은 수준에서 낮은 수준 블록으로 지식을 전달합니다. "Be your own teacher" (BYOT)는 출력 계층에서 얻은 지식을 각 낮은 수준 블록의 학습 과정을 안내하는 데 사용하는 대표적인 SD 알고리즘 중 하나
- 자기 학습(Self-distillation, SD)
- 이 논문의 연구
- SelfMatch
- BYOT의 고-저 수준 연결 접근 방식과 FixMatch의 여러 SSL 방법 통합에 영감을 받아, 우리는 레이블이 있는 데이터와 레이블이 없는 데이터에 숨겨진 표현을 포착하기 위한 robust한 semi supervised TSC 모델
- 감독 학습, 비감독 학습, 그리고 SD를 통합하여 시계열 데이터에 숨겨진 표현을 탐색
- supervised
- 레이블이 있는 데이터에 대한 교차 엔트로피 손실 함수를 사용하여 예측 벡터를 ground truth label로
- unsupervised
- FixMatch의 유사 레이블링 기술을 적용하여 레이블이 없는 데이터의 범주 간 관계를 포착
- (a) data augmentation 방법
- “약하게(Weakly)"
- 인공 레이블은 약하게 증강된 시퀀스(예: 원시 데이터에 가우시안 함수를 추가)를 기반으로 얻어지며, 모델에 시간절단 증강 버전의 동일 시퀀스가 제공될 때 목표로 간주됨
- "시간절단(Timecut)”
- 시계열 데이터에 대한 Cutout26의 수정된 버전으로, 주어진 시퀀스의 왜곡된 버전을 생성
- “약하게(Weakly)"
- (시계열 데이터가 이미지 데이터와 다르기 때문에, 우리는 FixMatch의 데이터 증강 방법을 TSC에 직접 적용할 수 없)
- (b) FixMatch에 따라, 우리는 가능한 클래스 중 하나에 충분히 큰 확률이 할당된 경우에만 인공 레이블을 유지
- (a) data augmentation 방법
- FixMatch의 유사 레이블링 기술을 적용하여 레이블이 없는 데이터의 범주 간 관계를 포착
- Self Distillation
- 고수준에서 저수준으로 지식 흐름을 안내하기 위해, 우리는 BYOT의 연결 접근법
- 출력 계층에서 얻은 지식이 낮은 수준의 각 블록에서 출력되는 지식을 감독
- BYOT가 Kullback-Leibler(KL) KD 손실 함수를 사용하는 것과 달리, SelfMatch는 고수준 및 저수준 특징 벡터 간의 차이를 측정하기 위해 L1 KD 손실 함수를 사용
- supervised
- SelfMatch
- Contribution !!

- 우리는 잔여 네트워크(ResNet)와 LSTM 기반 주의 네트워크(LSTMaN)를 SelfMatch의 특징 추출기로 결합했습니다. 즉, 그림 1의 ResNet-LSTMaN입니다. ResNet과 LSTMaN은 각각 데이터의 지역 및 전역 패턴을 추출하는 역할을 합니다.
- 우리는 SD 기술을 적용하여 출력 계층에서 얻은 의미 정보를 바탕으로 저수준 의미 정보의 추출을 감독합니다.
- 실험 결과, TSC를 위한 여러 SSL 알고리즘과 비교했을 때, SelfMatch는 UCR2018 아카이브에서 선택된 35개 데이터 세트 중 24개에서 우승했습니다. 이때 레이블이 있는 데이터가 훈련 데이터의 10%만을 차지했습니다. 레이블이 있는 데이터가 훈련 데이터의 30%를 차지할 때, SelfMatch의 성능은 35개의 UCR 데이터 세트에서 가장 낮은 감독 알고리즘인 Fast Shaplets(FS)에 근접합니다.
2. Related work
2.1 TSC algorithm
Currently, most of the TSC(시계열 분류) algorithms are either traditional‐based or deep‐learning‐based.
2.1.1 Traditional algorithms
- Distance‐based (NN+DTW)
- 데이터의 공간적 특징 간 유사성 측정
- ex. DTWI, DTWA
- DTW-NN 기반 앙상블 알고리즘
- ex. Lines와 Bagnall은 11개의 1-NN 기반 탄력적 거리를 결합한 것을 '탄력적 앙상블(EE)'이라고 하여 데이터 내의 중요한 차이점을 포착했습니다. Bagnall 등은 다양한 데이터 표현을 탐색하기 위해 여러 NN 기반 분류기를 가진 변환 기반 앙상블 방법 사용
- 데이터의 공간적 특징 간 유사성 측정
- Feature‐based
- ex. Baydogan 등은 시퀀스의 다른 위치에서 정보를 포착하는 특징 가방 표현 프레임워크를 고안했습니다.
- 단일 스캔 셰이플릿 알고리즘은 변형된 데이터 세트를 생성하는 데 사용되었습니다.
- Pei 등은 숨겨진 단위 로지스틱 모델을 구축하여 데이터 내의 잠재 구조를 구성했습니다.
- Bianchi 등은 다변량 시계열의 벡터형 고정 크기 표현을 생성하기 위한 저장소 컴퓨팅 방법을 제시했습니다.
- 알려진 여러 특징 기반 알고리즘에는 학습된 패턴 유사성, 심볼릭 푸리에 근사 심볼의 가방(BOSS), 시계열 포레스트(TSF), 다중 특징 사전 표현 및 앙상블 학습이 포함
2.1.2 Deep‐learning algorithms
목적: Intrinsic connections among representations
- 단일 네트워크 기반
- 일반적으로 하나의 (보통 혼합된) 네트워크를 사용하여 layer내의 중요한 상관관계를 포착
- ex. Lin 등은 TSC를 위한 정확도와 해석에 중점을 둔 종단 간 딥 뉴럴 네트워크 모델을 설계했습니다.
- 일반적으로 사용되는 딥 컨볼루션 뉴럴 네트워크(CNN), FCN, ResNet, InceptionTime, TSCaps, 그리고 인과성 확장 컨볼루션 인코더는 단일 네트워크 기반
- 이중 네트워크 기반 모델
- 하나의 local feature extract network + 하나의 global‐relationextraction network
- 하나의 local feature extract network
- CNN기반
- 하나의 global‐relationextraction network
- 추출된 특징 간의 관계
- 하나의 local feature extract network
- ex. RTFN, FCN-LSTM, 견고한 신경 시간 탐색, ResNet-Transformer, 그리고 주의력 프로토타입 네트워크(TapNet)
- 하나의 local feature extract network + 하나의 global‐relationextraction network
⇒ 레이블이 있는 데이터에 크게 의존
→ 이는 우리로 하여금 레이블이 적은 견고한 준감독 TSC 모델을 디자인하도록 동기를 부여
2.2 Knowledge distillation
KD는 (단순한) 학생 모델이 (복잡한) 교사 모델을 모방하게 하는 효율적인 지식 전달 방법
3. SelfMatch
3.1 Overview.
- ResNet–LSTMaN(특징 추출기)
- ResNet은 지역 패턴을 채굴하는 데 중점을 두고 LSTMaN은 전역 패턴을 발견
- supervised
- 대부분의 감독 알고리즘과 마찬가지로, 이 연구는 레이블이 있는 데이터의 예측 벡터와 실제 레이블 사이의 차이를 계산하기 위해 교차 엔트로피 손실 함수를 사용
- unsupervised
- weekly augmented 시퀀스가 인공 레이블을 생성하기 위해 사용되며, 모델에 timecut-augmented 버전의 동일 시퀀스가 제공
3.2 Problem formulation
3.3 Data augmentation
3.4 LSTM-based attention layer
- LSTMaN : 다양한 단변량, 다변량 데이터셋에서 좋은 성능 냄
3.5 Self‐Distillation
- 동시간에 teacher, student가짐
- transferring its knowledge from high‐level blocks to low‐level ones.


4. Experiments
4.4 Experimental analysis
- 다른 feature extractor들과 accuracy 비교
- 젤 잘 추출함!!
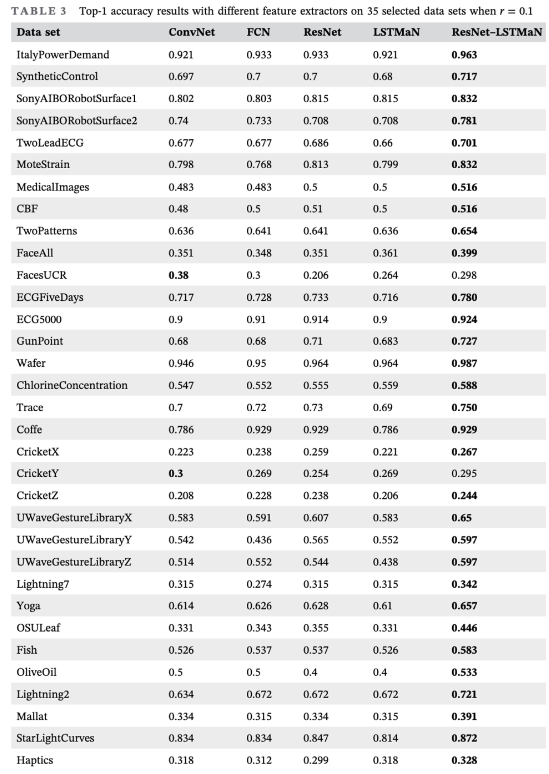
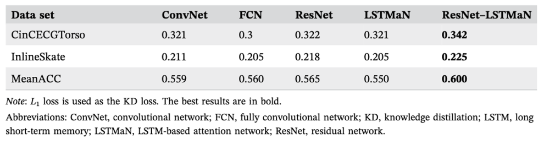
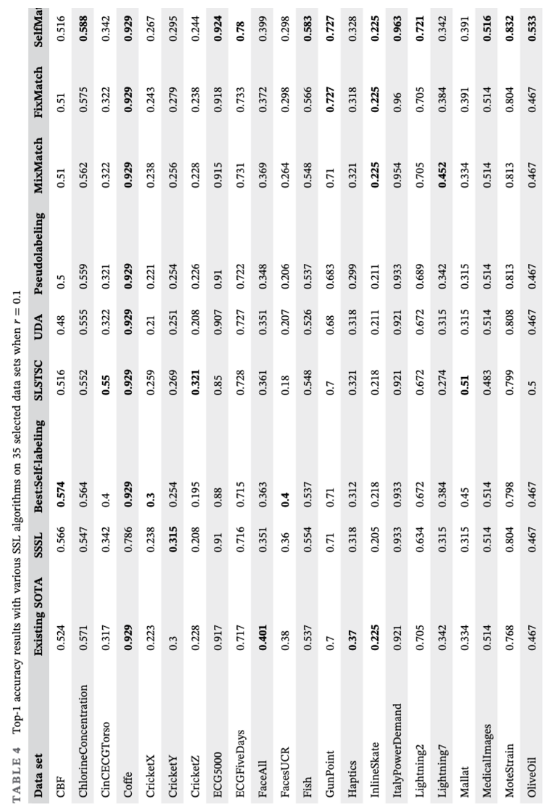
- 다른 ssl 알고리즘들과의 비교
- 젤 . 잘추출
Conclusion & Comments
- "SelfMatch"는 다양한 SSL 기술과 SD를 결합한 알고리즘
- ResNet–LSTMaN은 주요 특성 추출을 수행하는 역할
- SelfMatch는 레이블이 없는 데이터에서 클래스 간의 연결을 추출하고, SD는 의미 정보를 활용하여 하위 수준 의미 정보 추출을 지도.
- 실험 결과에 따르면 SelfMatch는 다양한 데이터 세트에서 우수한 성능.
- 하이퍼파라미터 설정이 중요하며, 자동 머신 러닝 방법을 사용하여 최적의 세팅 찾아야 함.