방법론의 목적
- 문제정의
- 현실 문제
- : 딥러닝 모델은 훈련 데이터와 유사한 분포에서는 높은 정확도를 보이지만, 도메인 시프트가 발생하면 성능이 크게 하락. 예) 카메라 노이즈, 날씨 변화, 센서 고장 등.
- 기존 한계
- : 일반적인 도메인 적응 방법은 소스 도메인 데이터를 다시 사용하거나, 테스트 환경을 미리 아는 경우에만 유효함.
- 현실적 제약
- : 테스트 시점에는 소스 데이터 접근이 불가능하거나 비용이 많이 드는 경우가 많음 (예: 개인정보보호, 제한된 리소스, 지연 시간 이슈 등)
- 목표
- Fully Test-Time Adaptation (FTTA): 사전 훈련된 모델의 구조와 가중치는 유지하며, 테스트 배치에서만 적응 수행
- : 소스 데이터 없이, 테스트 시점의 입력 데이터만으로 모델이 환경 변화에 적응하도록 만드는 방법론 제안
주목해야할 점 (Key Insights)
- 기존 TTA와의 차이점

- 핵심 통찰
- 엔트로피 최소화가 도메인 시프트 대응에 효과적이다
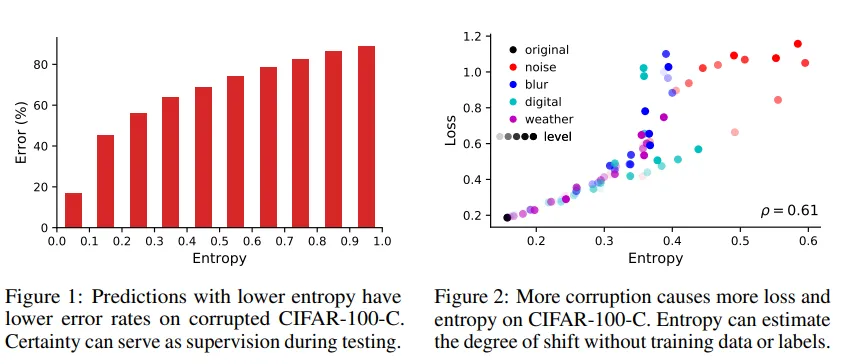
- : 테스트 배치에서 예측의 엔트로피를 줄이면 모델이 보다 확신을 갖고 예측 → 정확도 향상
- 엔트로피 최소화가 도메인 시프트 대응에 효과적이다
방법론
- 주요 아이디어
- 테스트 배치에서 예측 결과의 엔트로피를 최소화하는 방향으로 모델 일부를 업데이트
- 수식

- 구현방식
- 업데이트 대상: 오직 BatchNorm 레이어의 γ, β (scale, shift)만 업데이트 → 전체 파라미터 중 1% 미만 → 효율적이고 안정적
- : 전체 파라미터(θ)는 고정
- 알고리즘 흐름
- 초기화: γ, β 파라미터 수집. 기존 µ, σ는 제거
- 각 배치 입력마다
- µ, σ는 forward에서 추정
- γ, β는 예측의 엔트로피를 기준으로 gradient descent
- 다음 배치에서 업데이트된 γ, β를 사용
- 장점
- 빠름: 소수의 파라미터만 업데이트
- 안전함: 기존 모델 가중치 변경 없음
- 범용성: 다양한 CNN 구조에 적용 가능
실험
- 실험 목적
- TENT가 다음 조건에서 성능을 얼마나 개선할 수 있는지 확인
- 이미지 분류 문제에서의 도메인 시프트 (Corruption robustness)
- 다른 도메인으로의 generalization (Domain adaptation)
- 목표
- 기존 source-free TTA 기법 및 소스 데이터 기반 적응 기법과 비교하여 성능을 수치로 검증
- 완전히 테스트 시점에서만 적응하는 TENT의 효과 입증
- TENT가 다음 조건에서 성능을 얼마나 개선할 수 있는지 확인
- 데이터셋 구성 및 실험 환경
- Corruption Robustness
- Corruption 예시: ※ 각 corruption은 5단계 난이도로 변형되어 테스트됨
- : gaussian noise, motion blur, brightness, fog, jpeg compression 등
- Domain Adaptation: MNIST/MNIST-M/USPS: 손글씨, 흑백
- : SVHN: 실제 도로표지 숫자 (컬러, 배경 복잡)
- Corruption Robustness
- 모델 구성
CIFAR-10/100-C ResNet-26 (R-26) with BatchNorm ImageNet-C ResNet-50 (R-50) 표준 이미지넷 구조 Domain Adaptation R-26 동일 구조로 비교 공정성 확보 - → 모든 모델에 BatchNorm이 포함되어 있어 TENT 적용 가능 (γ, β 업데이트)
- Baselines
| Source | 학습된 모델을 그대로 테스트 | ✅ | ❌ |
| RG (Reverse Gradients, DA) | 도메인 불변 표현 학습 | ✅ | ❌ |
| UDA-SS | Self-supervised DA (rotation 등) | ✅ | ❌ |
| TTT (Test-Time Training) | source에서 self-supervised task 병행 학습 | ✅ | ✅ |
| BN (Test-Time Norm) | BN 통계만 업데이트 | ❌ | ✅ |
| PL (Pseudo-Labeling) | 예측 confident 결과를 label로 사용해 적응 | ❌ | ✅ |
| TENT (ours) | 엔트로피 최소화 기반 γ, β 업데이트 | ❌ | ✅ |
- Results
- CIFAR-10-C / CIFAR-100-C

- 분석
- TENT는 모든 기법 중 최저 오류율을 기록
- 특히 PL보다도 더 나은 성능을 보이면서 학습 방식은 훨씬 단순 (pseudo-label 생성 필요 없음)
- TTT보다 좋은 성능을 보이면서도 사전 학습 변경 없음.
- 분석
- ImageNet-C

- 분석
- 대규모 고해상도 이미지에서도 TENT는 가장 낮은 오류율 달성
- 학습 변경 없이 테스트 시점만으로 SOTA 초과 성능
- 기존에는 대규모 adversarial noise 학습 필요했던 성능을 online adaptation만으로 달성
- 분석
- SVHN → MNIST 계열 (Domain Adaptation)
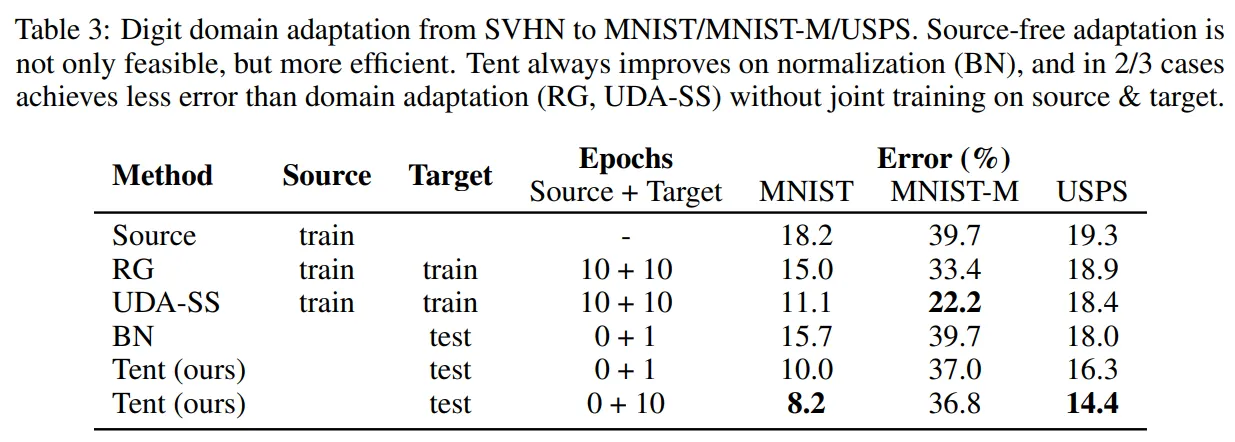
- 정량 수치는 논문에 간략히 언급되었지만, 주요 결과:
- TENT는 self-supervised loss 없이도 test-time adaptation 가능
- PL 대비 적응 속도 빠르고, confidence threshold 튜닝 필요 없음
- DA 기법과 유사한 성능을 비지도 방식으로 달성
- 정량 수치는 논문에 간략히 언급되었지만, 주요 결과:
- CIFAR-10-C / CIFAR-100-C
결론
- 주요 contribution
- Fully Test-Time Adaptation (FTTA) 문제 정의 및 공식화
- Entropy Minimization을 통한 실용적이고 효과적인 적응 기법 제안
- 소스 데이터, 라벨, 추가 모델 없이 SOTA 성능 달성
- 핵심 장점
- 데이터 효율성: 테스트 데이터만 필요
- 연산 효율성: γ, β만 업데이트
- 강력한 일반화 성능: 다양한 시나리오에서 향상된 정확도