방법론의 목적
- 문제 정의
- 소스 도메인의 데이터 접근 없이(unavailable source data) semantic segmentation 모델을 타겟 도메인에 적응시키는 source-free domain adaptation 문제를 해결.
- 목표
- Source-free domain adaptation (SFDA)
- : 오직 사전 학습된 모델 파라미터와 라벨 없는 타겟 데이터만으로 타겟 도메인에 적응하는 것이 목적.
- 하지만 naive self-training은 초기 예측 오류를 강화하는 문제(error accumulation) 발생.
- 따라서 "신뢰할 수 있는 예측만 선택적으로 학습"해야 함.
주목해야할 점 (Key Insights)
- Source-free setting이기 때문에 source data 없이 adaptation을 수행해야 함 → 매우 제한된 정보로 학습해야 하므로 정확한 pseudo-label filtering이 핵심.
- Pixel-level augmentation consistency라는 새로운 신뢰도 판단 기준 도입:
- 동일 이미지의 두 가지 augmented view에서 pixel-wise prediction이 일치하는 경우 해당 pixel을 신뢰할 수 있는 pseudo-label로 간주.
- 기존 방법들과의 비교에서 가볍고 빠르며 성능도 우수:
- 파라미터 업데이트는 batch normalization 계층에만 제한
- 추가적인 auxiliary module 불필요
- 한 epoch 내 수렴
방법론 (AUGCO (Augmentation Consistency-guided Self-training))
- 전체 구조
① Augmented view 생성 동일 이미지에 대해 색 변화(color jitter), 크롭(crop), 리사이즈(resize) 등으로 2개의 predictive view 생성 ② Reliable pixel 식별 두 view에서 동일한 pixel-wise prediction을 보이거나, 클래스별 confidence가 상위 K% 이상인 pixel을 reliable로 선택 ③ Selective Self-training 선택된 신뢰 가능한 pixel들에 대해 cross-entropy loss로 학습 진행 (다른 pixel은 무시) ④ Optimization 모델 전체가 아닌 BN parameter만 업데이트 (TENT [5] 방식과 동일)
- 핵심 수식 요약
- 신뢰도 측정 기준
- 최종 loss
실험
- 실험 세팅
- 3가지 Benchmark:
- GTA5 → Cityscapes
- SYNTHIA → Cityscapes
- Cityscapes → Dark Zurich Night
- 모델: DeepLabV3 (ResNet50), DeepLabV2 (ResNet101)
- Metric: mIoU (mean Intersection over Union)
- 3가지 Benchmark:
- 주요 결과
- GTA5 → Cityscapes (표 2 기준)
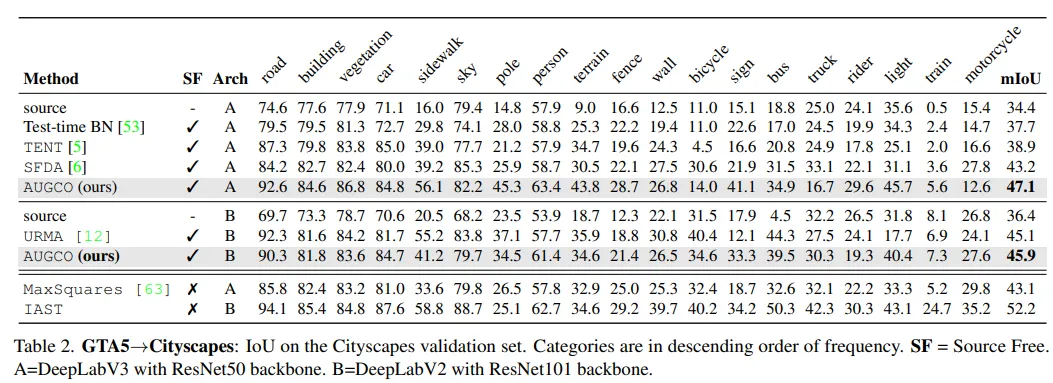
- 19개 카테고리 중 13개에서 SOTA 달성
- Auxiliary decoder 없이도 URMA보다 우수
- SYNTHIA → Cityscapes (표 3 기준)
- Cityscapes → Dark Zurich Night (표 4 기준)
- Ablation Study
- Ablation
- GTA5 → Cityscapes (표 2 기준)
→ Consistency가 가장 중요한 factor
→ Confidence는 단독으로는 효과 없음
결론
- 결론
- AUGCO는 단순한 구조, 빠른 수렴, 높은 성능을 보이는 Source-Free Semantic Segmentation의 효과적인 방법.
- augmentation consistency라는 새로운 self-supervised signal을 효과적으로 활용.
- 한계
- Tail class에서는 consistency가 덜 신뢰 가능한 신호일 수 있음
- Confidence threshold + extra forward pass로 인해 TENT보다 느림
- 완전히 unsupervised setting이라 여전히 silent failure 가능