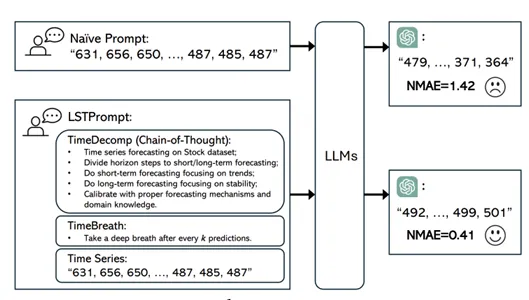
방법론의 목적 기존의 제로샷 TSF 프롬프트 전략은 TS 데이터를 숫자 문자열로 표현하고 TSF 작업을 텍스트 기반의 다음 토큰 예측으로 간주그러나 이러한 전략은 동적 TS 데이터에 내재된 정교한 예측 메커니즘의 필요성을 간과함.명확한 지침이 없으면 기존 전략은 높은 불확실성을 가진 부정확한 예측을 초래(=단순히 나열된 숫자만 가지고 다음을 예측하는 것은 예측에 필요한 다양한 요인들 고려안한것) 주목해야할 점 Chain-of-Thought, Time Breath 방법론 GPT-3.5 TurboGPT-4 사용 (best) Time Decomposition1) Chain-of-Thought목적: TSF 작업을 체계적인 추론을 위함방법: 특정 dataset으로 task prompt → task를 장단기 ..