1. Introduction
데이터셋 목적
: 감정상태와 생리학적 반응(PPG, EDA, 피부온도)간의 상관관계
: 기분 및 신체활동(=비수면 일상현상)포함
2. Related work

2.1. Activity datasets
- Opportunity
- 생활 실험실에서 4명의 피험자로부터 여러 온바디 IMU 및 환경 센서 데이터를 수집했으며, 이동 방식, 행동 및 객체를 나타내는 라벨을 포함하고 있습니다. PAMAP2 [4] 데이터셋은 손목, 가슴, 발목에 세 개의 IMU를 사용하고, 9명의 피험자가 착용한 심박수 모니터를 추가하여 걷기와 축구와 같은 다양한 활동에 대한 18개의 라벨을 포함하고 있습니다. UCI-HAR [1] 데이터셋에 포함된 IMU 데이터는 허리 왼쪽에 장착된 스마트폰으로부터 얻어진 것으로, 30명의 피험자가 6개의 활동 프로토콜을 수행했습니다. 이러한 데이터셋은 단순하고 저수준의 활동에 대한 실험 프로토콜에서 통제된 환경에서 수집되었기 때문에 복잡한 인간 행동의 다자 특성을 분석하는 데는 적합하지 않습니다.
- mHealth
- 10명의 피험자로부터 실험실 외부 환경에서 12개의 일반적인 일상 생활 활동(ADL)을 수집했으며, 스마트폰 앱이 활동 프로토콜 실행을 자체 기록했습니다. 이후 비디오 녹화 데이터를 실제 활동 라벨로 사용했습니다. 실험에서는 가슴, 오른쪽 손목, 왼쪽 발목에 세 개의 온바디 IMU와 가슴에 2개의 ECG 센서를 사용했습니다. 데이터 수집 프로토콜은 비제한적이었지만, 데이터셋은 단 2시간의 활동 데이터만을 포함
- ExtraSensory
- 60명의 피험자로부터 약 일주일(평균 7.6일) 동안 스마트폰과 스마트워치로 라벨이 지정된 센서 데이터를 비제한적으로 수집했으며, 참여 기간은 2.9일에서 28.1일까지 다양했습니다. 참가자들은 앱에서 제공하는 100개 이상의 라벨 중 관련 라벨을 선택하여 자신의 활동과 상황을 자가 보고했습니다. 데이터가 실제 환경에서 수집되었지만, 참가자 수나 실험 기간이 자연 조건에서 인간 행동의 장기적인 측면을 완전히 반영하기에는 충분하지 않았습니다. 기존 데이터셋은 활동 또는 상황에 중점을 두었으며, 심리적 또는 생리학적 상태를 나타내는 센서 데이터가 부족
2.2. Lifelog datasets
- NTCIR
- 정보 검색 연구 커뮤니티에서 제공하는 NII 시험장 및 정보 접근 연구 커뮤니티(NTCIR) 라이프로그 데이터셋 [15]은 라이프로깅을 정보 검색의 한 응용으로 취급합니다. 이 데이터셋은 두 명의 피험자가 30일 동안 기록한 약 26GB의 이미지, 위치 및 생체 정보를 포함하고 있습니다.
- ImageCLEF 라이프로그 데이터셋
- 크로스 언어 평가 포럼(CLEF) 그룹은 크로스 언어 주석 및 이미지 검색을 장려하기 위해 ImageCLEF 라이프로그 데이터셋 [14]을 지원합니다. 이 데이터셋은 두 명의 참가자로부터 1.5개월 동안 수집된 시각 데이터, 생체 정보 및 의미론적 내용을 포함
3. ETRI Lifelog dataset
3.1. System design
- 라이프로그 데이터의 3 가지 필수적인 측면: 행동적, 환경적 및 사회적, 생리학적 특성
- 사용한 시스템 3가지: 스마트폰, 손목에 착용하는 헬스 트래커, 수면 질 모니터링 센서
- 라벨링 비율
- 실험의 접근성과 실행 가능성을 결정하는 데 가장 중요하기 때문에,
- 자주 변경되는 저수준 활동(예: 앉기, 걷기, 서기, 눕기, 달리기)은 생략
- 고수준 행동에 대해서만 라벨링함
- 장기 실험은 시간이 지남에 따라 참여도를 저하시킬 수 있으므로, 오랜 기간 동안 실험의 충실도를 유지하는 것이 고려
3.2. Lifelogging system architecture
안드로이드 스마트폰의 모바일 앱
- 라벨링 UI
- 생활 시간 조사를 기반으로 일상 활동을 라벨링
- 활동: 16개의 고급 옵션으로 계층적으로 표시
- 맥락 라벨: 동반자 여부, 사회적 상호작용의 강도, 장소 정보
- 감정: Russell의 원형 모델을 따라 두 축으로 표현
- 애플리케이션: 반복되는 일상이나 미리 예정된 일정을 입력할 수 있는 인터페이스를 제공


- 데이터 수집
- 3축 관성 센서: 50Hz로 샘플링되었고, GPS 좌표는 5초마다 기록
- 마이크로폰의 오디오 입력: 매 30분마다 22,050Hz로 기록되어 배경 소음과 주변 환경을 캡처
- 기록된 오디오 데이터: 스마트폰에서 처리되어 40ms 프레임마다 30ms 중첩으로 구성된 13개의 멜 주파수 켑스트럼 계수를 추출
- 전화 상태 정보: 활동 유형과 애플리케이션 사용 통계가 포함
- 활동 유형: Google Awareness API에서 매 분마다 장치 상태(예: 차량 내, 자전거, 도보, 정지, 알 수 없음)를 나타내도록
- 애플리케이션 사용 통계: 30분마다 포그라운드에서 실행 중인 애플리케이션의 지속 시간을 캡처
- 날씨 정보: GPS 위치에서 온도, 습도 및 대기 오염 농도(PM 10 및 PM 2.5)를 포함한 날씨 정보는 AirVisual API를 사용하여 획득
- 사용자 통계
- 장기적인 라이프로그 트렌드를 파악
- 모든 참가자의 평균도 함께 표시되어 실험 결과를 다른 사람들과 비교 가능
- 데이터 전송
- 사용자 라벨과 센서 데이터는 실험 세션 동안 로컬 저장소에 누적되며 사용자가 실험을 종료할 때마다 WiFi 네트워크를 통해 데이터 수집 서버로 전송
손목에 착용하는 건강 추적기
- 의료 등급의 생리 신호 및 행동 데이터를 얻기 위해 Empatica E4 손목 밴드를 사용합니다.
- 3축 가속도계 데이터: 32Hz로 샘플링되고, 혈압은 PPG 센서를 통해 64Hz로 측정됩니다.
- 피부 전도 값: EDAsensor에서, 주변 피부 온도는 적외선 온도계에서 각각 4Hz의 샘플링 속도로 기록됩니다.
- 사용자는 E4 장치를 USB 인터페이스를 통해 PC에 연결하여 로컬 메모리에 저장된 센서 데이터를 검색합니다.
- Empatica의 E4 매니저 소프트웨어가 데이터를 자동으로 Empatica의 클라우드 서버에 업로드합니다.
- 실험 운영자는 클라우드에서 데이터를 수동으로 가져와 우리의 라이프로깅 서버에 저장
수면 질 모니터링 센서
- 개인의 일상과 수면의 질 사이의 가능한 관계를 조사하기 위해 야간 수면 데이터를 수집합니다.
- Withings 수면 추적 매트를 사용하여 설치하고, 스마트폰에 설치된 Withings Health Mate 애플리케이션을 통해 네트워크 연결을 설정합니다.
- 수면 데이터: Withings 클라우드 서버에 자동으로 업로드되며, 우리의 라이프로깅 서버는 주기적으로 Withings 데이터 API를 통해 데이터를 가져옵니다.
- 수면 데이터: 수면 중 각성, 얕은 수면, 깊은 수면 및 REM 수면의 지속 시간을 포함한 다양한 수면 질 측정이 포함됩니다.
- 또한 수면의 시작 및 종료 시간, 잠드는 데 걸리는 시간, 깨어나는 시간 등의 일반 정보도 제공됩니다.
3.3. Data collection protocol
기본 정보(실험기간, 참가자 수, 참가자 연령, 참가자 직업)
- 실험 기간: 2020년 8월 30일부터 2020년 10월 8일까지이며,
- 참가자수: 대한민국의 대도시에서 남성 13명, 여성 9명으로 구성되었습니다.
- 참가자들의 연령: 20세에서 35세 사이이며,
- 참가자 직업: 대부분은 주중에 정기적으로 출퇴근하는 사무직 근로자였습니다.
- 보고된 바에 따르면, 모든 참가자는 주 3일 이상 근무했습니다.
- 이로 인해 대부분의 참가자는 28일 연속 실험 기간을 완료했습니다.
참가자 실험 중의 정보(실험 최소 시간, 수면 질 설문지)
- 실험 최소 시간: 참가자들은 아침에 일상을 시작하여, 매일 최소 12시간 동안 데이터를 수집했습니다.
- 수면 질 설문지: 아침에 자가 보고되었습니다.
- 참가자들은 실험 기간 동안 신체 활동, 의미 있는 장소, 사회적 상태 및 감정 등 맥락의 변화를 라벨링하도록 지시받았습니다.
- 참가자들은 수면과 관련된 두 번째 설문지를 작성했으며, 여기에는 스트레스 인식 수준*(신체적 및 정서적 스트레스의 정도)*과 수면 전날 동안의 카페인 및 알코올 음료 섭취량이 기록되었습니다.
- 12시간 실험이 끝나면 참가자들은 데이터를 서버로 전송했습니다.
- 실험 감독자는 매일 데이터 품질을 관리하고 참가자들이 실험에 적극적으로 참여하도록 독려했습니다.
참가자 실험 이후의 정보
- 실험이 끝난 후, 우리는 실험 프로토콜과 사용된 장치들에 대해 설문 조사를 실시했습니다.
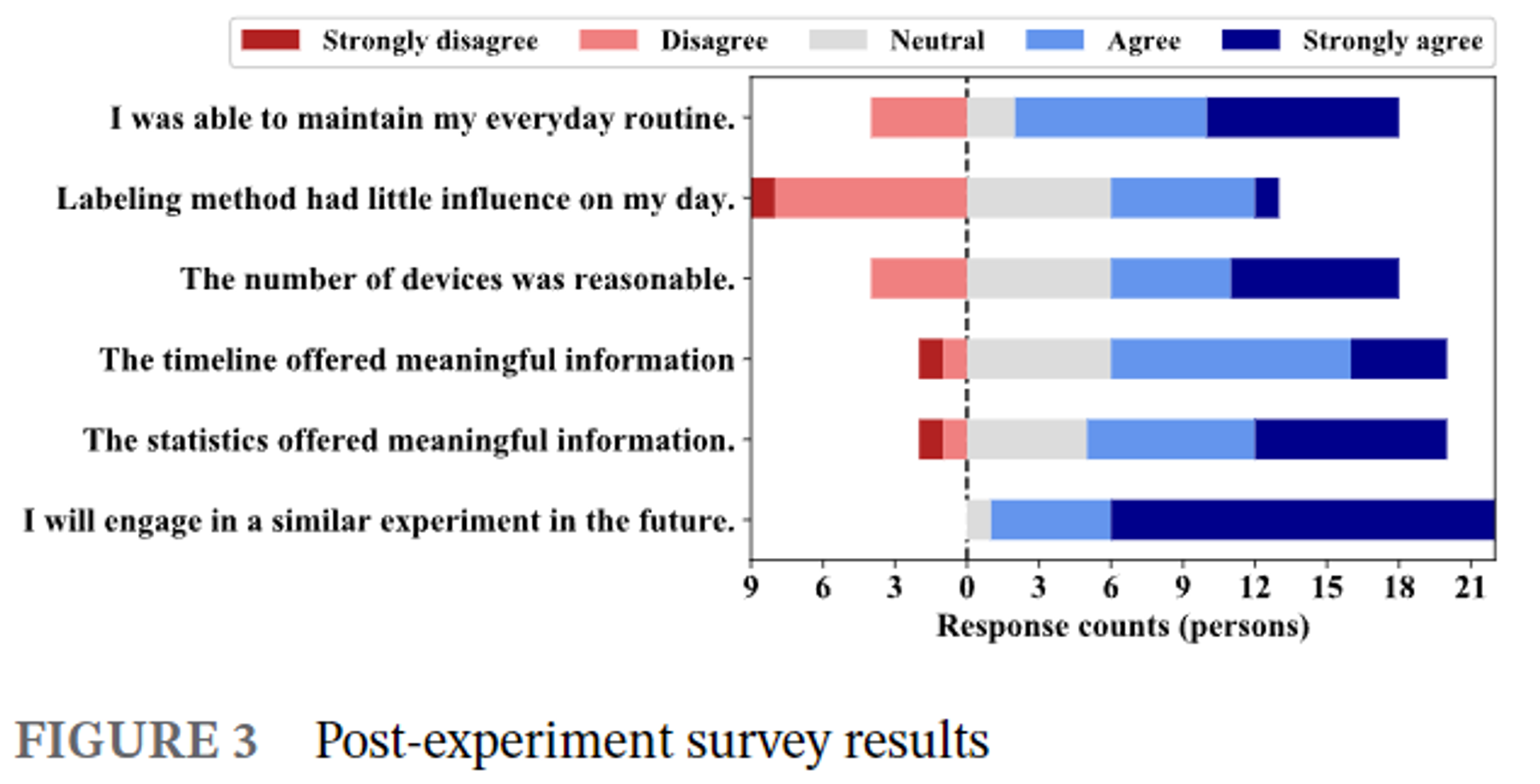
- 22명의 참가자 중 81.8%는 일상 루틴을 유지했으며, 실험 동안 관리된 장치 수가 합리적이라고 답변했습니다.
- 31.8%의 참가자는 라벨링 방법이 일상 생활에 약간의 불편을 초래했다고 응답했습니다.
- E4 손목 밴드는 제한된 사용자 인터페이스로 인해 가장 방해가 되는 장치로 63.6%의 응답을 기록했습니다.
- 90.9%의 참가자들은 통계적 라벨이 일상 경험을 정리하는 데 유익하고 유용하다고 응답했습니다.
- 95.5%의 참가자들은 추가 실험에 참여하고 싶다고 답했으며, 59.1%는 동일한 프로토콜로 4주 이상 실험을 계속할 의향이 있다고 답했습니다.
3.4. Dataset statistics
수집한 데이터 전반 특징
- 우리는 총 2.26TB 이상의 데이터를 축적했습니다.
- 이 데이터에는 의미 있는 활동, 장소, 사회적 상태 및 감정을 나타내는 10,372개의 사용자 라벨이 포함되어 있습니다.
- 행동 특성을 나타내는 데이터: IMU 데이터, GPS 좌표, 활동 유형, 앱 사용 통계를 나타내는 전화 상태로 구성됩니다.
- 환경 데이터: 주변 소음을 반영하는 오디오 특징과 날씨 정보를 포함합니다.
- 표 4에 따르면, 우리의 데이터셋은 ExtraSensory 데이터셋보다 두 배 많은 데이터를 포함하고 있습니다.
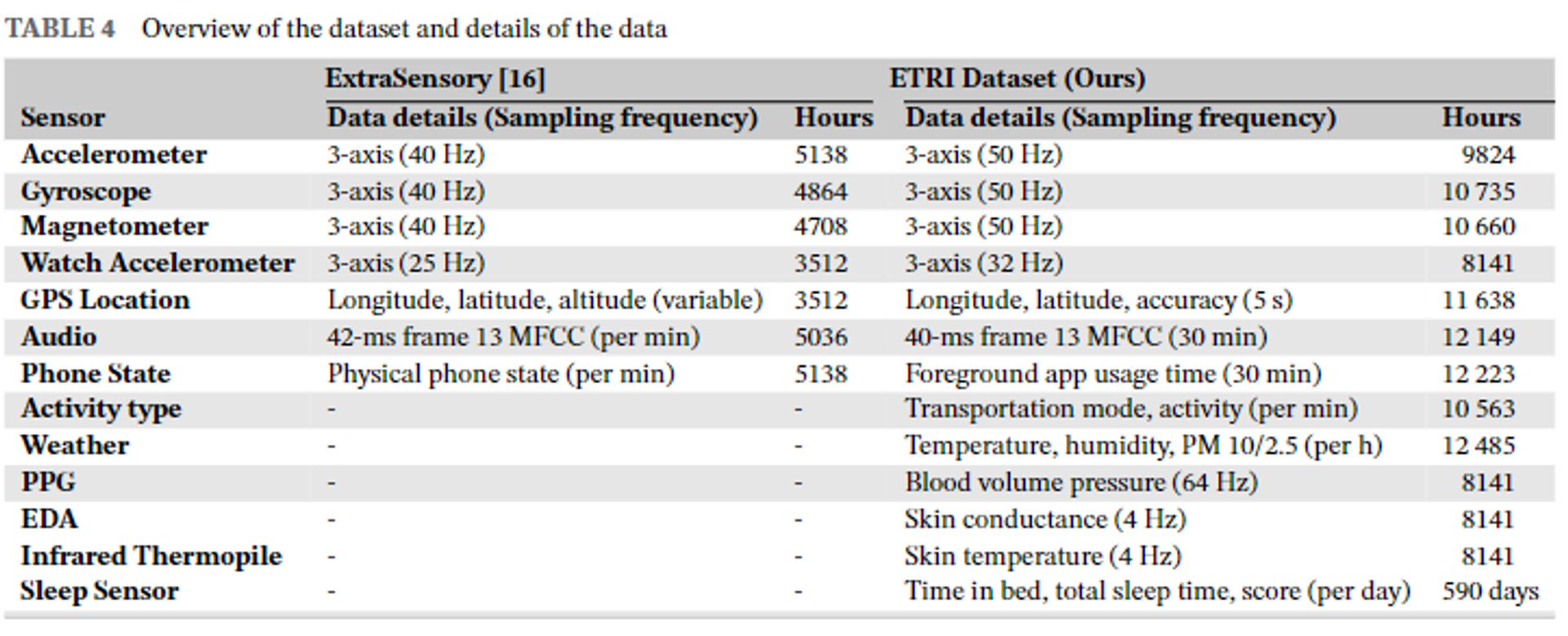
- 우리의 데이터셋에는 8,141시간의 생리 데이터와 590일 동안의 야간 수면 질 측정이 포함되어 있습니다.
- 우리는 활동 및 라이프로그 데이터와 함께 실제 환경에서 수집된 생리 데이터를 포함하는 가장 큰 데이터셋을 소유하고 있다고 주장할 수 있습니다.
⇒ 생리학적 데이터와 수면 질 측정 데이터 포함된게 가장 큰 특징인듯
활동, 장소, 사회적 상태 및 감정 라벨 분포 통계
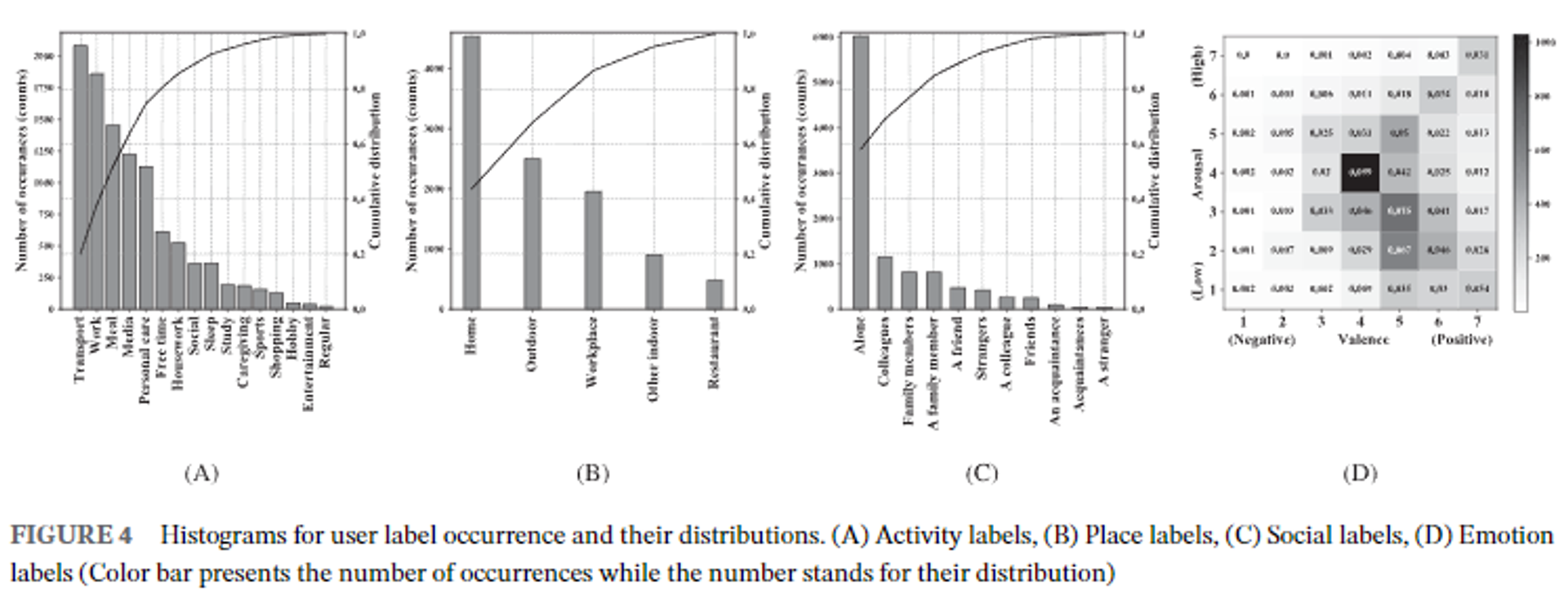
- 활동 라벨(A): 큰 비중(89.2%)을 차지하는 8가지 주요 활동은 교통(20.1%), 작업(17.9%), 식사(14.0%), 미디어(11.8%), 개인 관리(10.9%), 자유 시간(5.9%), 가사(5.1%), 사회적 활동(3.5%)입니다.
- 장소 라벨(B): COVID-19 팬데믹에 대응하여 많은 참가자들이 예상치 못하게 재택 근무를 했습니다.
- 그 결과, 장소 라벨의 43.8%가 집이었으며, 18.8%만이 직장으로 표시되었습니다.
- 사회적 상태 분포(C): 대부분의 라벨(58.0%)이 참가자들이 사회적 상호작용이 거의 없는 혼자 있을 때 태그되었음을 보여줍니다.
- 감정 라벨(D): Russell의 원형 감정 모델에 따라 2D로 표시된 감정 라벨
- 7점 척도의 쾌락 및 각성 척도는 각각 x축과 y축에서 범주 1(부정적)에서 범주 7(긍정적), 범주 1(이완)에서 범주 7(활성화)까지의 범위를 갖습니다.
- 범주 4는 쾌락과 각성 척도 모두에서 중립 상태를 나타내며, 7점 A-V 척도의 49가지 조합 중 가장 많이 발생했습니다(9.9%).
- 낮은 각성, 긍정적 쾌락 상태(IV 사분면)는 감정 라벨의 가장 큰 비율(37.3%)을 차지했습니다.
- 그 다음으로 높은 각성, 긍정적 쾌락 상태(I 사분면, 19.4%), 낮은 각성, 부정적 쾌락 상태(III 사분면, 6.0%), 높은 각성, 부정적 쾌락 상태(II 사분면, 4.5%)의 순서로 나타남
4. Applications of the dataset
4.1. HAR(인간 활동 인식)
적용 목적
- 목적: 저수준 활동(걷기 또는 앉기)을 예측하는 인간 활동 인식(HAR)에 중점을 둡니다.
- 우리의 실험은 장기간에 걸쳐 실제 시나리오의 데이터를 축적했습니다.
- 사용자 라벨: 저수준 활동은 라벨링 정확도 떨어짐**(=**고수준의 활동 또는 의미적 맥락(출퇴근)과 더 밀접하게 일치할 수 있으며, 저수준 활동의 단계 변화와 높은 정밀도로 일관되지 않을 수 있습니다.)
- 예를 들어, 출퇴근 중에는 걷기와 앉기가 번갈아 발생할 수 있지만, 행동 중에 저수준 활동을 즉시 라벨링하는 것은 거의 불가능합니다.
- 따라서 Google Awareness API의 활동 유형 데이터는 **'도보', '정지', '차량', '알 수 없음'**의 네 가지 클래스에 대한 저수준 활동의 기준 데이터를 제공합니다.
4.2. Human behavior pattern extraction
각 사용자의 일일 행동 패턴을 추가 조사
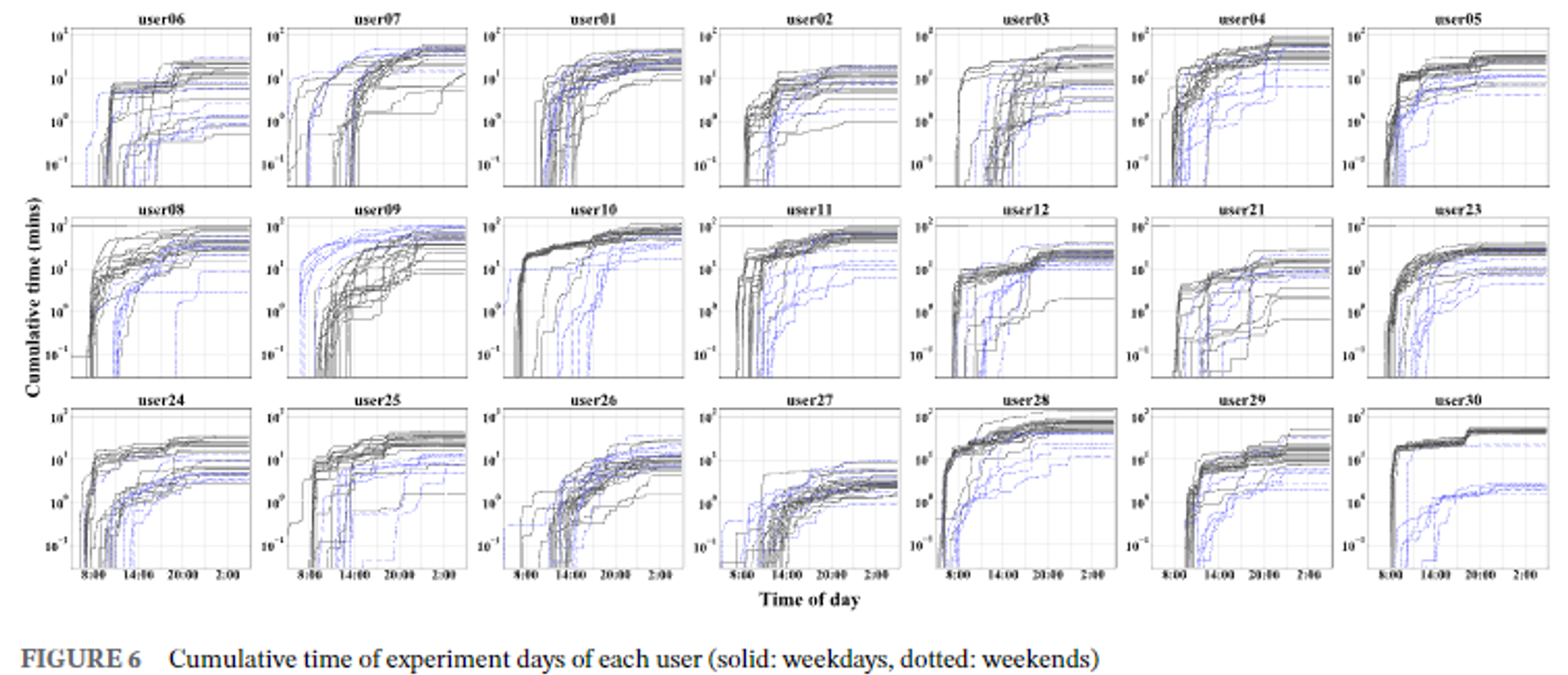
- 센서 데이터 스트림에서 활동 인식 결과를 추출하고, 10분마다 활동 발생을 누적하여 단위 시간 내 활동 분포를 나타냄.
- 일일 행동 패턴을 설명하기 위해, "걷기"로 인식된 누적 시간을 조작하여 활성 부분을 특징 벡터로 고려했습니다.
- 특징 벡터: 24시간을 10분 단위로 나타내는 144개의 슬롯으로 구성되며, 오전 5시부터 시작