Abstract
- 이전 UDA 방법: 지역x 전역 초점
- 제안모델: SLARDA
- 자기감독 학습 모듈 → 예측에 활용하여 source 특성의 전이성 개선
- 도메인 정렬 → 도메인 정렬 동안 소스 및 타겟 특성의 시간 의존성을 통합하는 새로운 자기회귀 도메인 적응 기술을 제안
- confidence pseudo labeling(앙상블 teacher모델) → target domain에서 class별 분포 정렬
Introduction
- DL 기반 접근 방식은 항상 훈련 데이터(즉, 소스 도메인)와 테스트 데이터(즉, 타겟 도메인)가 동일한 분포에서 추출되었다고 가정
- 비전 UDA: MMD, GAN 방식 많이 사용
- 시계열 적용의 어려움
- 동적 특성 포착 어려움
- 기존 pretrain모델은 imageNet기반, 시계열에 부적합
- 시계열 기존 연구 흐름: adversarial하게 도메인 불변 특성 찾음
- 기존 연구 문제점
- 소스, 타겟 discriminator → 시간 차원 무시 → 쉽게 속이기 ㄱㄴ
- 전역o, 지역x(도메인 내 세밀한 class분포 고려x)

- 자기감독 자동회귀 도메인 적응(SLARDA) 프레임워크
- 계열 도메인 적응을 위한 자기감독 사전 학습 (기존엔 없었음)
- 특성 정렬 동안 시계열 데이터의 시간 의존성을 통합 위해, 새로운 자동회귀 도메인 적응 접근 방식을 제안
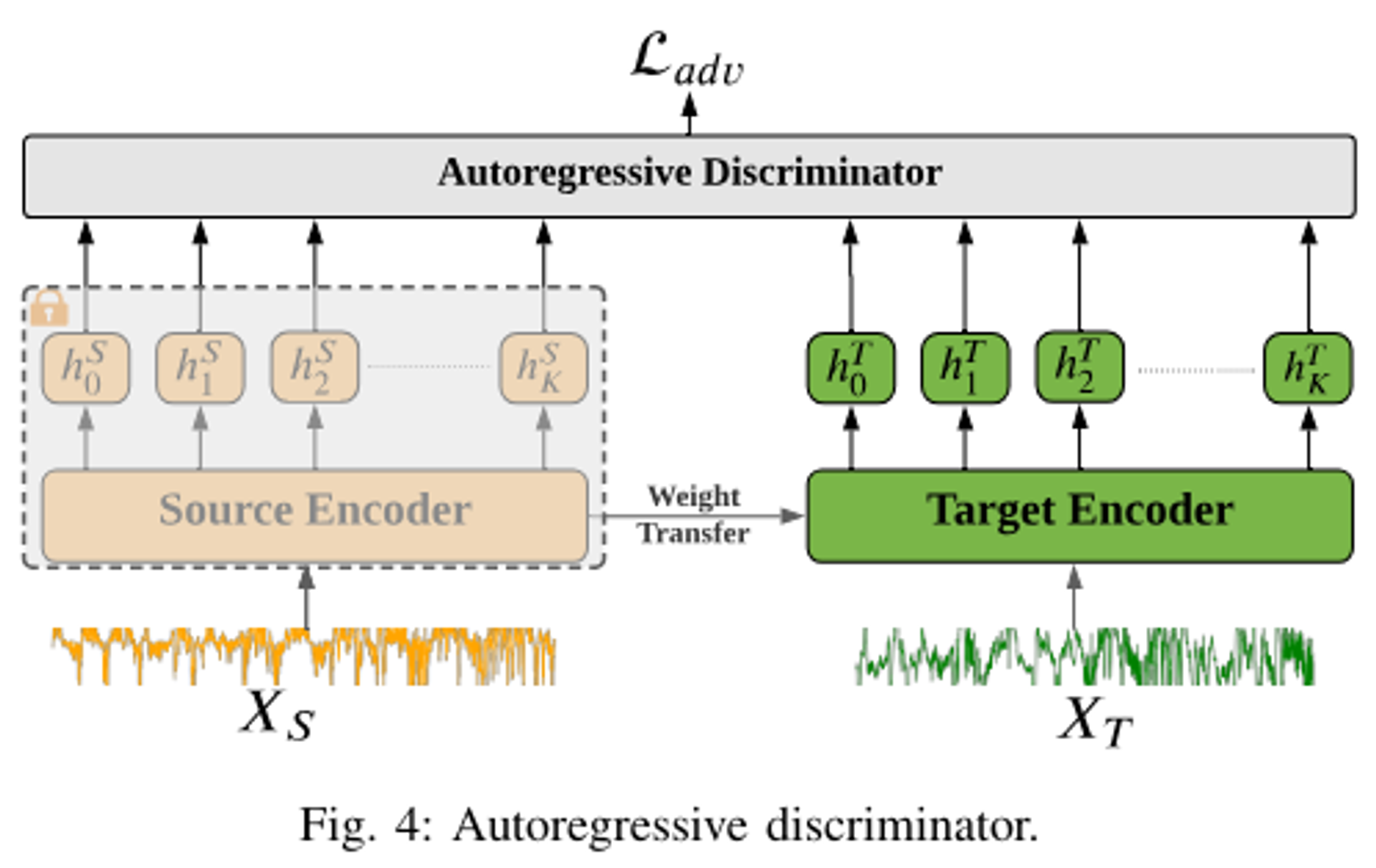
- 소스 및 타겟 특성을 분류할 때 시간 차원을 고려하는 자동회귀 도메인 차별자를 개발하여 기능 추출기가 더 나은 특성을 학습하도록
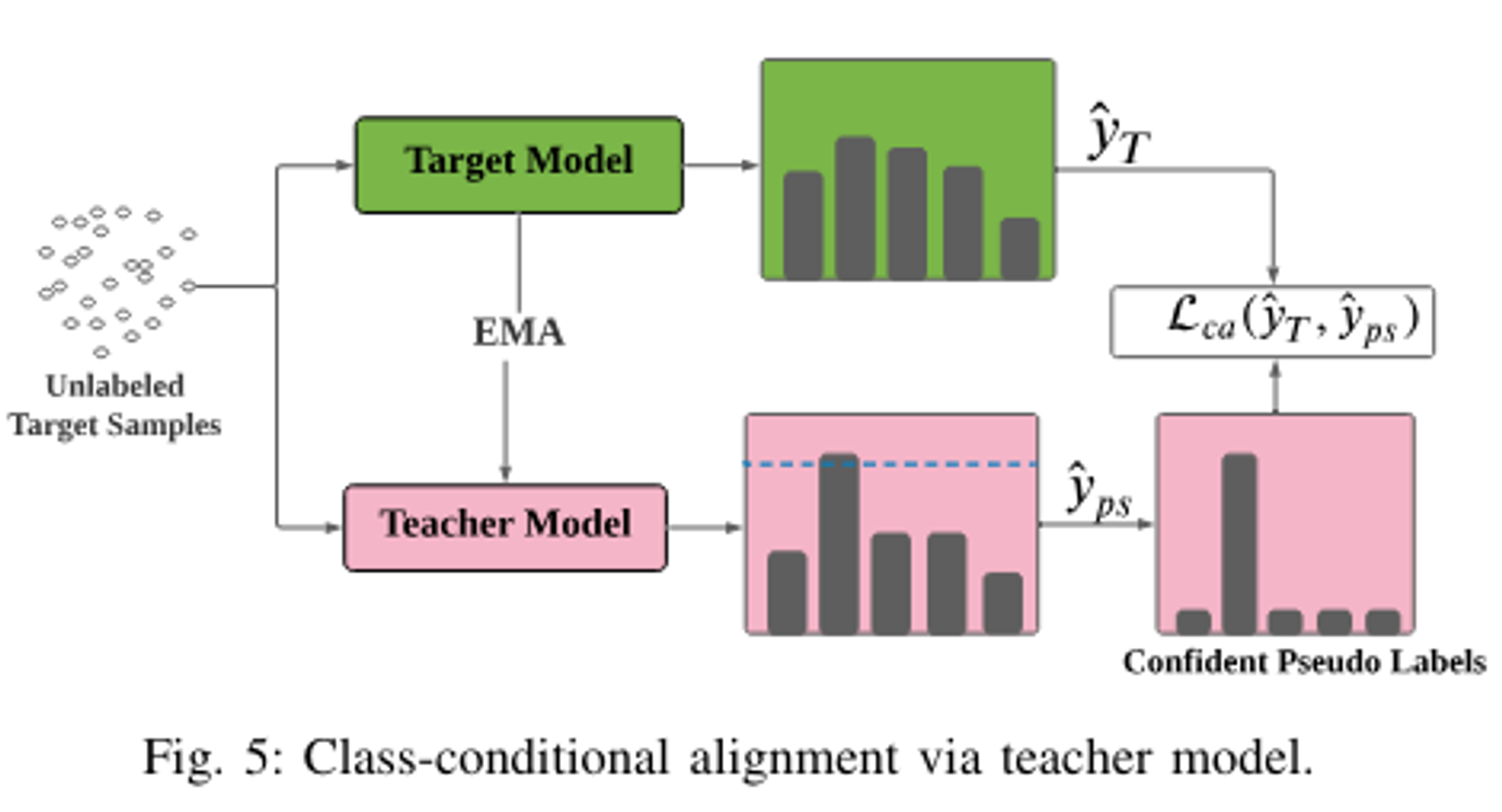
- 소스 및 타겟 도메인 간의 class conditional shift를 완화하기 위해, 우리는 confidence pseudo labeling을 사용하여 타겟 모델을 안내하고 세밀한 소스 및 타겟 클래스를 정확하게 정렬
- contribution
- 우리는 소스 도메인에 대한 자기감독 사전 학습을 개발하여 학습된 특성의 표현 학습 및 전이성을 개선합니다. 우리의 지식에 따르면, 우리는 시계열 도메인 적응을 위한 자기감독 사전 학습을 제안하는 최초의 연구자입니다.
- 도메인 정렬 중 소스 및 타겟 특성 간의 시간 의존성을 고려하기 위해, 우리는 시계열을 위한 자동회귀 도메인 차별자를 설계했습니다. 이는 기능 학습 및 도메인 정렬의 성능을 향상시킬 수 있습니다.
- 우리는 도메인 정렬을 위해 타겟 도메인에서 신뢰할 수 있는 의사 라벨을 생성할 수 있는 앙상블 교사 모델의 의사 라벨링 접근 방식을 제안합니다. 이는 소스 및 타겟 도메인 간의 클래스 조건적 시프트를 완화할 수 있습니다.
III. METHODOLOGY
A. Problem Formulation
- 소스 도메인과 타겟 도메인의 샘플은 단변량 또는 다변량 시계열
B. Overview of SLARDA

C. Self-supervised Learning for Source Pretraining

D. Autoregressive Domain Adaptation.
E. Class-conditional Alignment via Teacher model