0. Abstract
- 레이블이 지정된 훈련 데이터(소스 도메인)의 분포가 **레이블이 없는 테스트 데이터(타겟 도메인)**의 분포와 다르다는 도메인 이동 문제가 일반적으로 발생
- 제안점(롤링 베어링 결함진단 위한 새로운 도메인 적응 방법)
- Deep CNN 사용됨
- 다중 레이어에서 두 도메인 간의 다중 커널 최대 평균차이(MMD) 최소화하여,
- 소스 도메인에서 supervised learning 통해 학습된 표현이 타겟 도메인에 적용될수있도록
1. Introduction
[1] rolling element bearing과 domain shift 문제 정의
- rolling element bearing
- 중공업 기계, 제조 시스템 등에서 중요한 구성 요소, 현대 산업에서 널리 적용됨
- 장기간 운영 중 예상치 못한 베어링 결함은 유지 보수 비용이 크게 발생하고 안전성이 손실되는 원인이 됨
- 수집된 신호를 신속하고 효율적으로 처리/ 신뢰할 수 있는 결함 진단 결과를 제공/ 사전 전문 지식을 요구하지 않는 데이터 기반 지능형 결함 진단 방법이 점점 더 인기
- domain shift 문제
- 실제 응용에서는 환경, 운영 조건, 베어링 품질 등의 변화로 인해 훈련 데이터와 테스트 데이터의 분포가 서로 다르게 되어, 레이블이 지정된 훈련 데이터(소스 도메인으로 표시됨)에서 학습된 패턴 지식을 새로운 레이블이 없는 테스트 데이터(타겟 도메인으로 표시됨)에 적용할 때의 일반화 능력이 저하
[2] 간단한 Domain adaptation 개요

Fig1: 소스 도메인과 타겟 도메인간의 분류 오류와 분포 차이 최소화 → 도메인 이동 해결
[3] 전통적인 신호 anomaly detection
- 전통적 기계 고장 신호분석
- 웨이블릿 분석, 확률공진 기술
- 최근 10년간 기계고장 신호분석
- ANN, SVM, RF, 퍼지추론 및 기타 개선 알고리즘
- 고장진단 → 특징 추출 통해 classification 문제가 됨 (추출된 특징 따라 건강상태와 해당 고장위치, 심각도 식별)
[4] 고장 진단을 위한 주요 구조로 딥 러닝이 사용
[5] domain adaptation 개요
- 도메인 적응(DA)
- 소스 도메인의 레이블이 지정된 데이터를 활용하여 → 타겟 도메인의 레이블이 없는 데이터에 대한 분류기를 학습하는 transfer learning
- 감정 분석, 다양한 상황에서의 객체 인식, 얼굴 인식, 음성 인식, 비디오 인식 등 많은 실용적인 작업에 성공적으로 개발되고 적용됨
- 필요성
- 도메인 차이(domain shift)
- 도메인 간에 잘 훈련된 모델을 적용하는데에 문제점
- 두 도메인은 동일한 분포를 따르지 않음
- ex. 동일한 고장 위치 및 심각도 분류 작업에 대해, 다른 회전 속도 및 모터 부하에서 데이터의 분포가 크게 다를 수 있음
- 도메인 차이(domain shift)
- 레이블이 없는 타겟 데이터를 사용하여 소스 도메인에서 훈련된 기존 모델을 적응시키거나, 모든 사용 가능한 데이터로 새로운 모델을 개발함으로써 달성 가능
[6] domain invariant feature 학습
- domain invariant feature
- 도메인 불변 구조를 탐색하여 소스 도메인에서 타겟 도메인으로 분포 차이를 연결
- 얕은 도메인 불변 특징이 학습
[7] 도메인 차이 발생 문제점
- 도메인 차이 발생 문제점
- 도메인 차이가 증가함에 따라 상위 레이어에서 feature의 전이 가능성이 크게 떨어짐
- 하위 레이어가 도메인 편향에 더 많이 발생할수도
[8] 도메인 적응 + 고장 진단
: 소스 도메인 데이터는 타겟 데이터 분류를 돕기 위한 보조 데이터로 사용
- 한정적인 연구
- Lu 등은 특징 최대 평균 차이(MMD)를 최소화하고 대표적 특징을 강화하기 위해 가중치 정규화 항을 사용하는 진단을 위한 딥 뉴럴 네트워크 기반 도메인 적응 방법을 제안
- Zhang과 동료들은 신경망의 도메인 적응 능력을 향상시키기 위해 적응형 배치 정규화 방법을 제안
- Xie 등은 스펙트럼 봉투 사전 처리와 시간 도메인 동기화 평균 원리를 사용하여 시간 및 주파수 도메인에서 교차 도메인 특징 추출 및 융합에 관해 연구
[9] 제안점
- 베어링 고장 진단을 위한 새로운 딥 컨볼루션 신경망 기반 도메인 적응 방법
- input: 기계 진동 데이터
- 레이블이 지정된 소스 도메인 데이터와 레이블이 없는 타겟 도메인 데이터 사용 가능
- 차별점
- 소스와 타겟 도메인 데이터 간의 다층 및 다중 커널 최대 평균 차이(MMD)를 최소화하여 도메인 이동 문제를 해결
- input: 기계 진동 데이터
2. Theoretical background
2.1. Problem formulation
- 문제 정의: 전이학습

- 가정
- 다른 도메인에 대해 고장 진단 작업은 동일하게 유지되며, 즉 클래스 레이블이 공유됩니다.
- 소스와 타겟 도메인은 서로 관련이 있지만, 분포가 다릅니다.
- 훈련을 위해 소스 도메인의 레이블이 지정된 샘플이 사용 가능합니다.
- 훈련 및 테스트를 위해 타겟 도메인의 레이블이 없는 샘플이 사용 가능합니다.
- 최종 목적
- 결합 분포에서의 도메인 간 변화를 줄이고 도메인 불변 특징 및 분류기를 학습할 수 있는 딥 신경망 y=f(x)를 구축하는 것.
- 이를 통해 소스 감독 하에 타겟 위험 Rt(f)=Pr(x,y)∼Q[f(x)=y] 을 최소화하기 위함
2.2. Maximum mean discrepancy (최대 평균 차이)
- 사용 목적: 분포간 차이 측정 위함
- 재생 커널 힐버트 공간(RKHS)에서 마진 분포의 커널 임베딩 사이의 제곱 거리로 정의됨
- 주요 성질
- Hk= 특성 커널k로 구성된 RKHS
- MMDk(P,Q)=0이면 그리고 그럴 때에만 P=Q
- 커널 선택 (중요)
- : MMD의 testing power와 testing 오류 보장 위해 중요(서로 다른 커널은 확률 분포를 서로 다른 RKHS에 임베딩, 다른 순서의 충분통계강조)
- (이 연구에서,,) 다양한 커널 사용하여 여러 커널의 MMD 채택 → 최적 커널 선택 위한 원칙적 접근법 구성
- 예시: N_k개의 RBF 커널 혼합 사용
- 주요 성질
2.3. Convolutional neural network
3. Proposed fault diagnosis method
3.1. Network architecture
필터 수는 10개이고 필터 길이는 10이며, 완전 연결 층은 최종 회귀를 위해 256개의 뉴런을 가짐
3.2. Optimization objective
- 최적화 목표 - 1) train sample의 분류 오류 최소화
- loss function: cross entropy loss (Lc)
- 최적화 목표 - 2) 두 분포간의 다중커널 MMD 최소화(= network내 은닉층 통해, 두 domain 분포의 feature representation 가까워지도록)
- 기존 연구) 네트워크 마지막층에서 분포 차이 최소화
- 기존 연구 한계) 특징 전달성은 여러 상위layer에서 이미 저하됨
- 마지막층(단일층)에만 적응시킨다해서 편향제거X
- 다른 층에서 전달 못할수있기 때문 (ex. 1번층이 나중 층보다 도메인 이동에 더 취약
- : source domain에서 훈련된 분류기 → target domain 일반화 위해 사용
⇒ (다중커널 MMD사용해서) representation layer와 classifier를 함께 적응시키는 DA 개발
→ 주변 분포&조건부 분포 모두에 내재된 차이 극복
- MMD 손실

- L: 손실이 계산되고 있는 층
- K: 커널 집합
- Pl,Ql : 소스/타겟 샘플의 l번째 층 표현
- MMDk(Pl,Ql) : 커널k를 사용하여 l번째 층 표현에서 평가된 소스/타겟 도메인간 MMD

- 전체 손실
- α : 기본값이 1인 constraint 계수
- MMD 손실
- L: 손실이 계산되고 있는 층
- K: 커널 집합
- Pl,Ql : 소스/타겟 샘플의 l번째 층 표현
- MMDk(Pl,Ql) : 커널k를 사용하여 l번째 층 표현에서 평가된 소스/타겟 도메인간 MMD
- 전체 손실

- α : 기본값이 1인 constraint 계수
- MMD 손실
- α : 기본값이 1인 constraint 계수
3.3. Diagnosis procedure
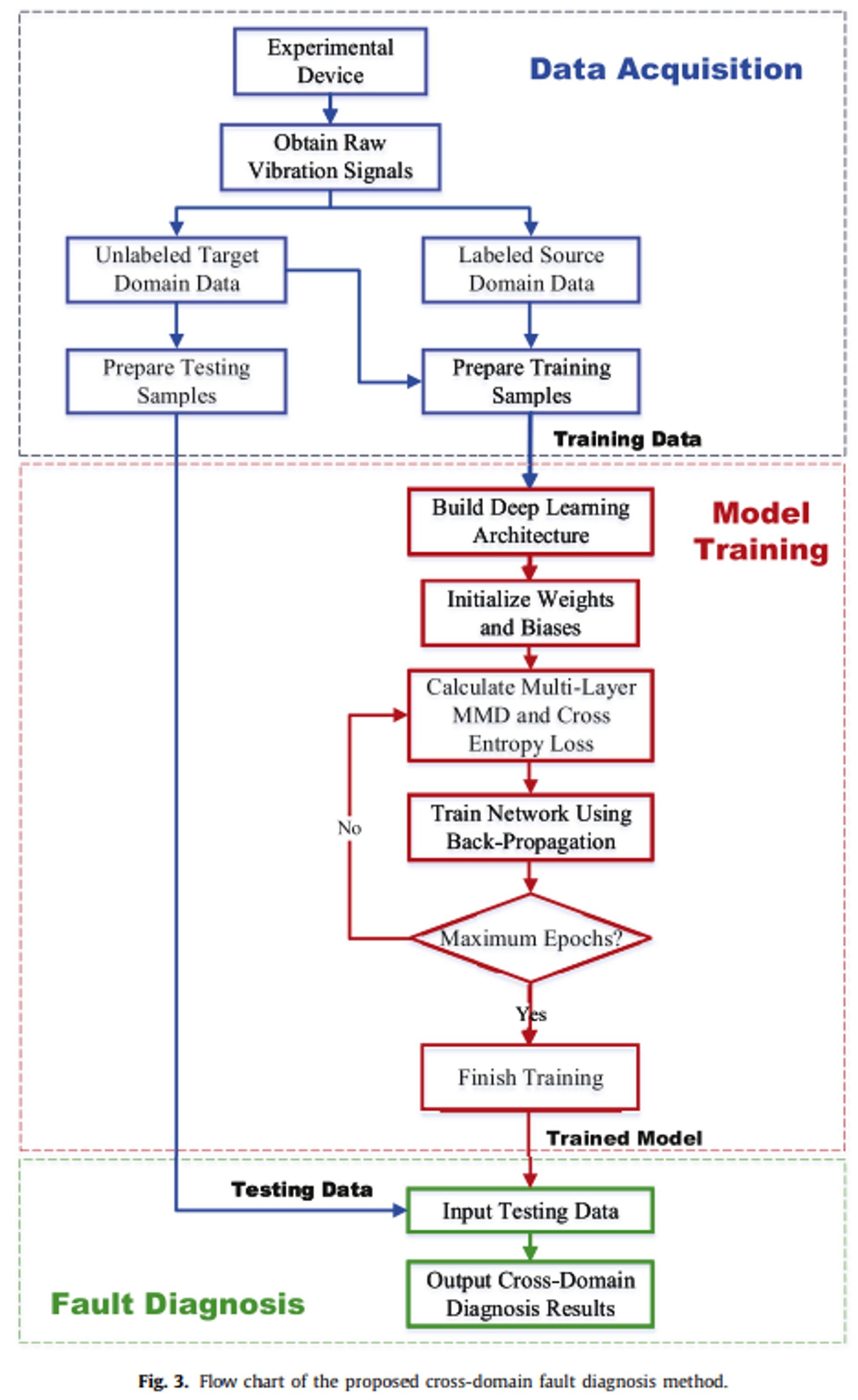
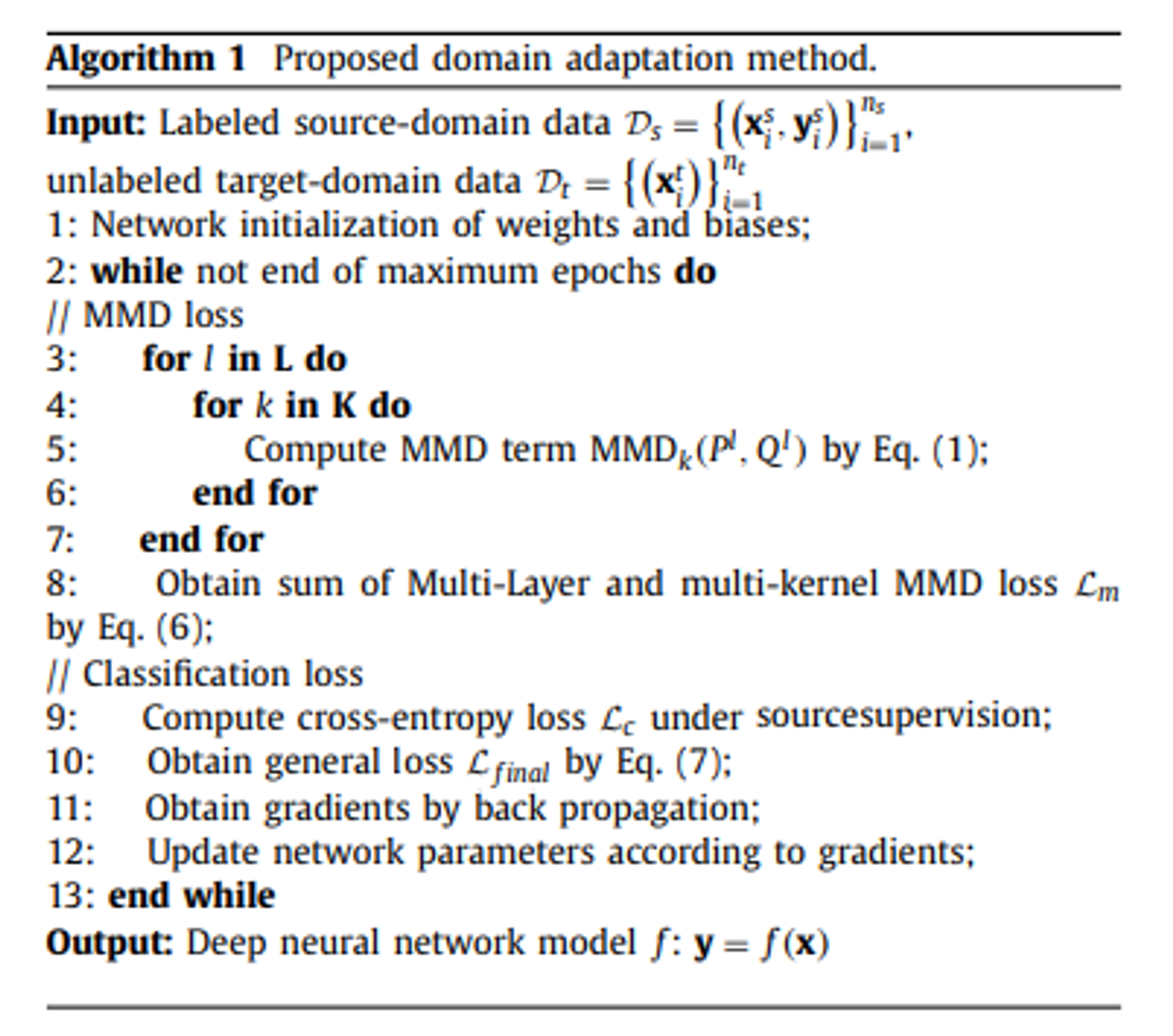
4. Experimental study
4.1. CWRU experimental setup
- 데이터셋 및 수집 방법
- 롤링 베어링 데이터셋
- 가속도 변환기 통해 0,1,2,3hp의 4가지 하중 조건에서 데이터 수집
- 정상 상태, 외부 레이스 결함, 내부 레이스 결함, 볼 결함의 4 가지 health condition을 포함
- 각 결함 유형은 7 mils, 14 mils, 21 mils의 세 가지 결함 직경으로 생성
- 결함의 특성 분석 방법
- 1) 진동 데이터로 분석
- : 롤링 베어링이 작동할 때, 베어링에 결함이 있으면, 그 결함 부위가 베어링의 다른 부분과 충돌하면서 특정한 패턴의 진동이 발생합니다. 이러한 진동은 가속도 센서에 의해 감지되며, 이 데이터는 다양한 하중 조건 하에서 수집됩니다. 하중이 다르면 베어링의 회전 속도가 달라지고, 이에 따라 진동 데이터의 분포도 달라짐
- 2) 주파수 데이터로 분석
- 시간 도메인 신호 → 주파수 도메인 변환(빠른 푸리에 변환(FFT)를 사용)
- 베어링 결함으로 인해 발생하는 특성주파수 확인 및 분석 가능
- 특성주파수는 결함 유형, 위치에 따라 달라짐
- ex. 외부 레이스에 결함이 있을 경우 볼 패스 주파수 외부 레이스(BPFO)가 나타나며, 내부 레이스 결함은 볼 패스 주파수 내부 레이스(BPFI)를 생성합니다. 기본 열차 주파수(FTF)와 볼 회전 주파수(BSF)도 마찬가지로 특정 결함 상태를 나타내는 주파수
- 특성주파수는 결함 유형, 위치에 따라 달라짐
- 베어링 결함으로 인해 발생하는 특성주파수 확인 및 분석 가능
- 모델 평가 방법
- transfer 작업을 통한 평가
- T01, T02, T03, T30, T31, T32의 여섯 가지 전송 작업을 통해 평가
- 다양한 운영 상황에서 모델의 전이성을 평가하기 위함
- 각 health condition에 대해 선택된 Nsou 및 Ntar 샘플은 소스 도메인 및 타겟 도메인 데이터로 사용
- transfer 작업을 통한 평가
- 데이터셋 구성과 샘플링 방법
- 데이터셋: 10가지 health condition 포함(정상부터 다양한 결함까지/각 상태는 1부터 10까지 번호로 구분)
- 샘플링: 데이터는 특정 길이(120,000점)로 잘라서 분석할 샘플을 만듦
- → 잘린 각 샘플은 소스(학습용) 또는 타겟(테스트용) 데이터로 사용
4.2. Compared approaches (method들 설명)
: 동일한 데이터셋으로 최신 관련 연구도 제안된 방법의 효과성과 우수성을 보여주기 위해 제시
- 6가지 접근방식의 연구
- 다층 다중 커널 통합(MLMK-I-(x)) 방법
- 다층 구조 + 여러 커널(필터)로 베어링 결함진단
- ML(multilayer), MK(multikernel), I(Integration Goal), -(x)(특징 MMD(최대 평균 차이)가 최소화되는 레이어)
- ex. ML-MK-I-(1,2,3,4,fc) : 모든 은닉층에서 MMD 손실을 최소화하는 상황
- MK-I 접근방법
- 기존) unsupervised domain adaptation → 마지막 레이어에서 분포 차이 최소화
- 최종 완전 연결 레이어에서만 MMD를 고려하여, 제안된 다층 MMD 방법의 우수성 보여줌
- ML-I-(x) 접근방법
- 다중 커널 MMD에 의한 성능 향상을 보여주기 위해
- 대역폭 매개변수가 4인 하나의 MMD 커널을 사용
- 제안된 방법에 해당하는 ML-I-(1,2,3,4,fc)가 비교를 위해 구현
- T-S 접근방법
- 소스-타겟 도메인 데이터 모두사용X
- 소스 특정 네트워크에서 타겟 특정 네트워크로 학습을 전환하는 적응 방법
- 소스 특정 네트워크로 훈련한 후, 비슷한 새로운 타겟 특정 네트워크를 구축하여 레이블이 없는 타겟 도메인 데이터로 훈련
- 두 네트워크 간의 레이어 분포 차이를 최소화하는 것이 새 네트워크의 최적화 목표
- 2단계 학습 접근 방법
- 식 (7)의 통합 목표가 분리되어, 초기화 후 일반 네트워크를 소스 및 타겟 도메인 데이터와 함께 추가로 훈련하여 레이어 간 분포 차이를 최소화
- 한계: 네트워크 가중치가 적절한 규제 없이 거의 0에 가까워질 가능성
- 도메인 적응 없는 전통적 훈련 방법(Without-DA)
- 소스 도메인 데이터만을 사용하여 모델을 학습하고, 타겟 도메인 데이터에 대한 적응 과정을 거치지 않음
- cross entropy loss만 사용(모델이 학습 데이터에 잘 맞도록 하지만, 새로운 또는 약간 다른 데이터 분포에 대한 모델의 일반화 능력은 크게 향상시키지 않을 수 있습니다. )
- 도메인 적응 기법들과 비교하여 모델의 성능을 평가하는 기준점으로 사용
- 다층 다중 커널 통합(MLMK-I-(x)) 방법
4.3. CWRU experimental results and performance analysis(실험결과)
4.3.1. Results on the rolling bearing dataset
4.3.1.1. Transfer task T03
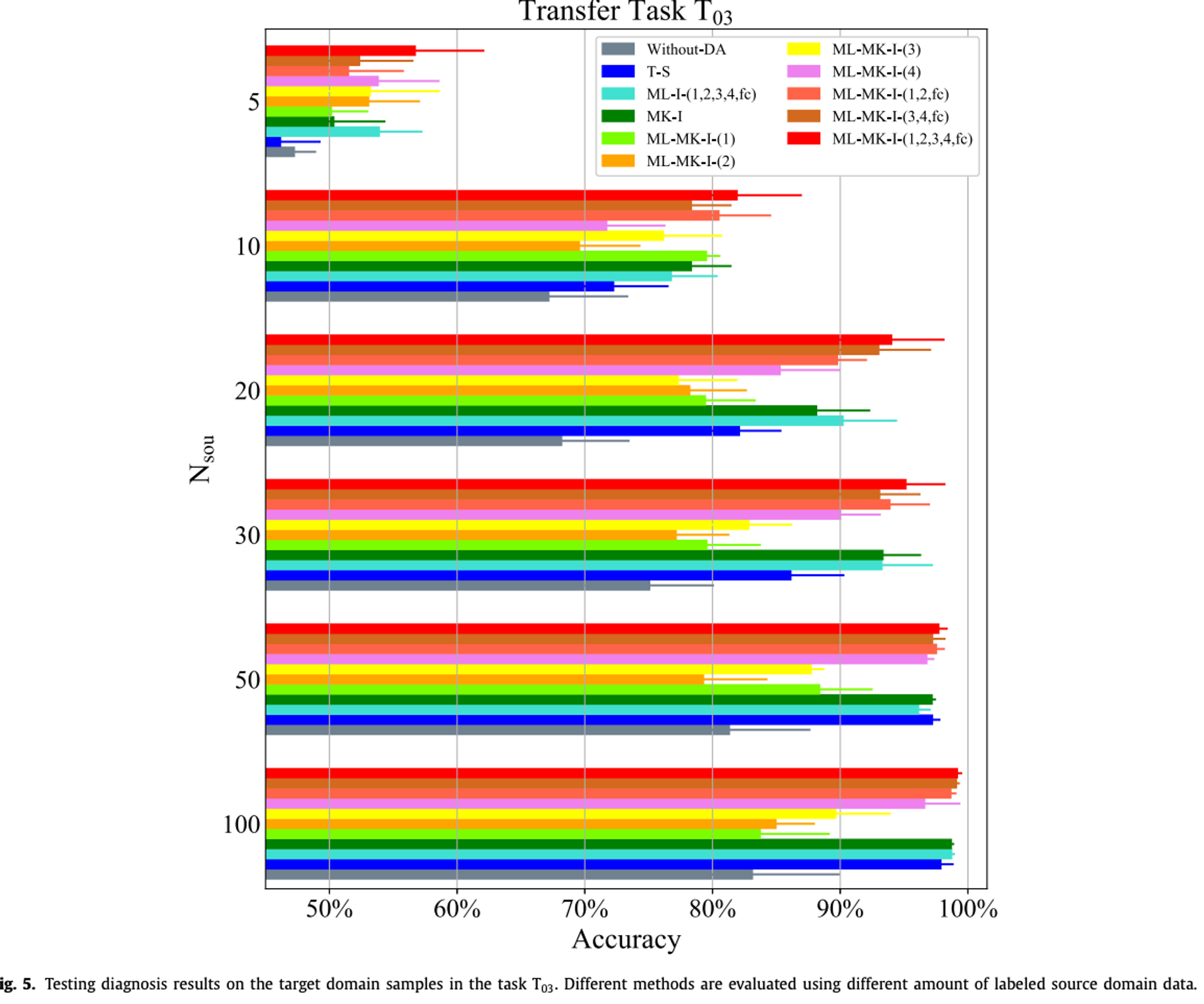
- 전체: 다양한 양의 소스 도메인 데이터 바꿔가면서 성능 측정
- 결과 해석
- 1) 더 많은 레이블이 있는 소스 도메인 데이터로 훈련할수록 모든 방법의 테스트 정확도가 증가
- : 훈련 샘플이 네트워크 성능에 중요
- 2) 도메인 적응을 통해 상당한 개선이 가능함을 일반적으로 관찰
- : Without-DA 방법을 사용할 때 낮은 테스트 정확도가 관찰되었으나, 도메인 적응을 사용한 나머지 방법들에서는 테스트 정확도가 현저히 향상
- 3) 제안된 방법이 모든 시나리오에서 최고의 진단 성능을 달성
- : ML-I-(1,2,3,4,fc) 방법으로 얻은 테스트 정확도는 제안된 방법보다 일반적으로 낮았으며, 이는 제안된 다중 커널 MMD에 의한 개선을 보여줌
- **4) 단일 레이어(**MK-I 방법) MMD 최소화를 사용하는 진단 접근법도 평가됨
- : 마지막으로 연결된 레이어에서의 분포 차이를 최소화하는 MK-I 방법은 비교적 좋은 결과를 제공했으나, 나머지 접근법들은 Without-DA 방법에 비해 제한적인 개선만을 달성
- 5) 다중 레이어 MMD 방법의 변형인 ML-MK-I-(1,2,fc)와 ML-MK-I-(3,4,fc)도 평가되었으며, 만족스러운 결과를 얻었지만 제안된 방법보다는 약간 낮았음
- : 도메인 적응에는 다중 레이어 MMD가 교차 영역 문제에 잘 맞으며, 모든 레이어에서의 분포 차이를 고려하는 것이 선호됨
- 6) T-S 방법은 대안적인 도메인 적응 방법을 제공
- : 큰 레이블이 있는 훈련 데이터셋을 사용할 때 좋은 테스트 결과를 달성합니다. 그러나 Nsou가 작아질수록 진단 성능이 크게 떨어짐
⇒ 최종 결론) 제안된 방법의 효과가 짱임
- 특히 작은 훈련 데이터셋을 사용할 때 다른 접근법에 비해 제안된 방법에 의한 개선이 더 눈에 띔
- 제안된 방법은 유효하고 레이블이 붙은 훈련 데이터를 얻기 어려운 산업 응용 분야에서 큰 잠재력을 가지고 있음
4.3.1.2. The other five transfer tasks.
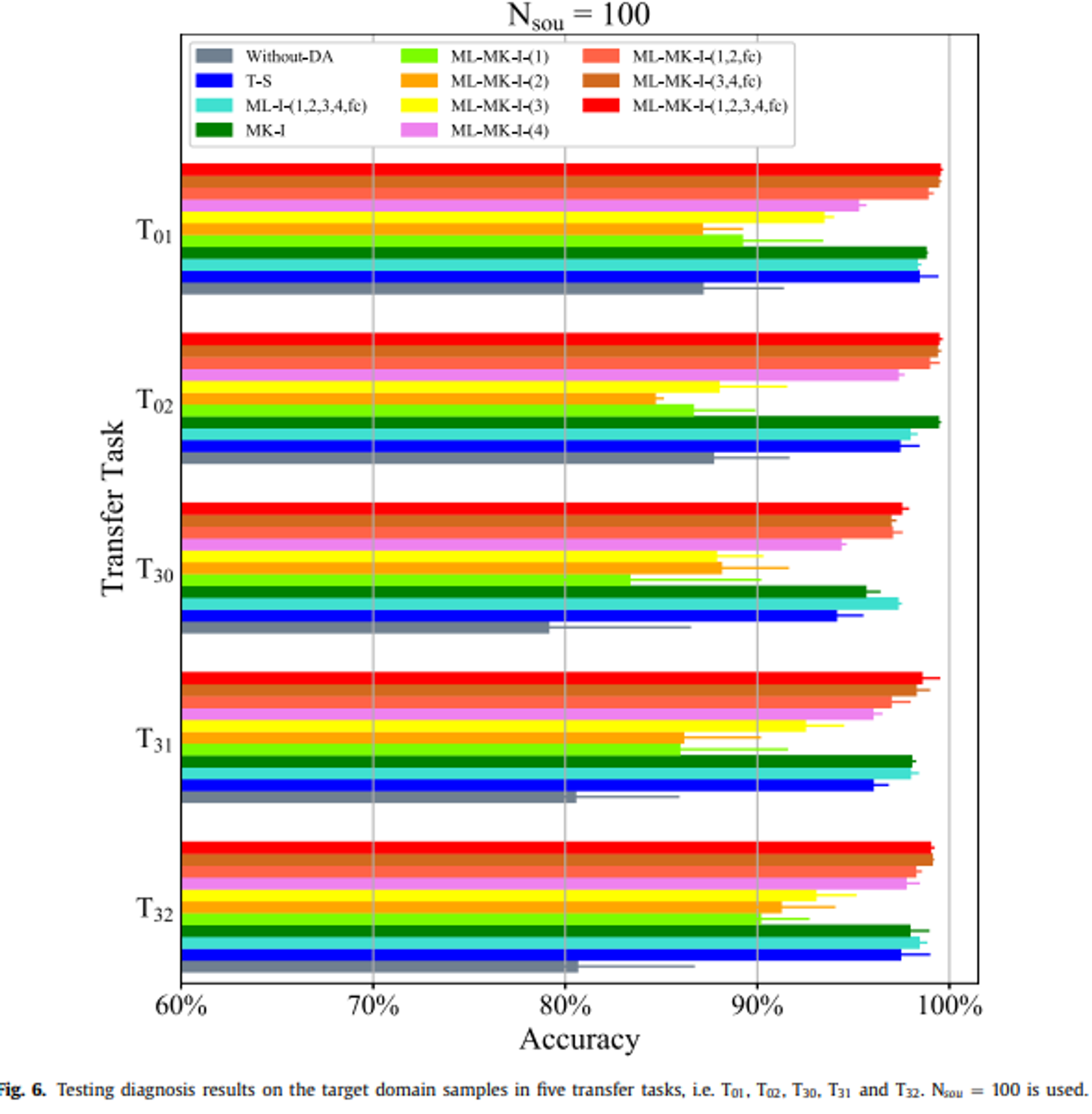

4.3.2. Visualization of learned representation
: 완전 연결 레이어의 시각화 제시
: 일반적으로 마지막 숨겨진 레이어가 교차 도메인 문제에서 매우 중요
- 분석 특징
- PCA로 50차원으로 줄이고 → t-sne로 2차원 맵으로 변환
- T03에서 제안된 방법(ML-MK-I-(1,2,3,4,fc))을 사용한 특징의 시각화와 도메인 적응 없이(Without-DA) 사용한 특징의 시각화

- 결과 해석
- 제안된 방법
- 다양한 조건에서 모든 데이터 샘플을 잘 분리하여 최적의 군집화를 달성(높은 결함 진단 정확도를 위한 기본적인 요구 사항)
- 소스 및 대상 도메인의 좋은 수렴이 관찰(동일한 결함 클래스에 속하는 두 도메인의 샘플은 대부분 동일한 지역으로 군집하며, 소량의 교차 도메인 데이터 중첩만 관찰)
- Without-DA
- 제안된 방법과 동일한 네트워크 구조를 사용하여, 동일한 health-condition 라벨을 가진 샘플이 잘 군집하지만, 소스와 대상 도메인 사이에는 상당한 분리가 관찰
- 결함 클래스에 대해, 동일 클래스의 두 도메인은 동일 지역으로 군집화 X
- 제안된 방법
4.3.3. Layer distribution
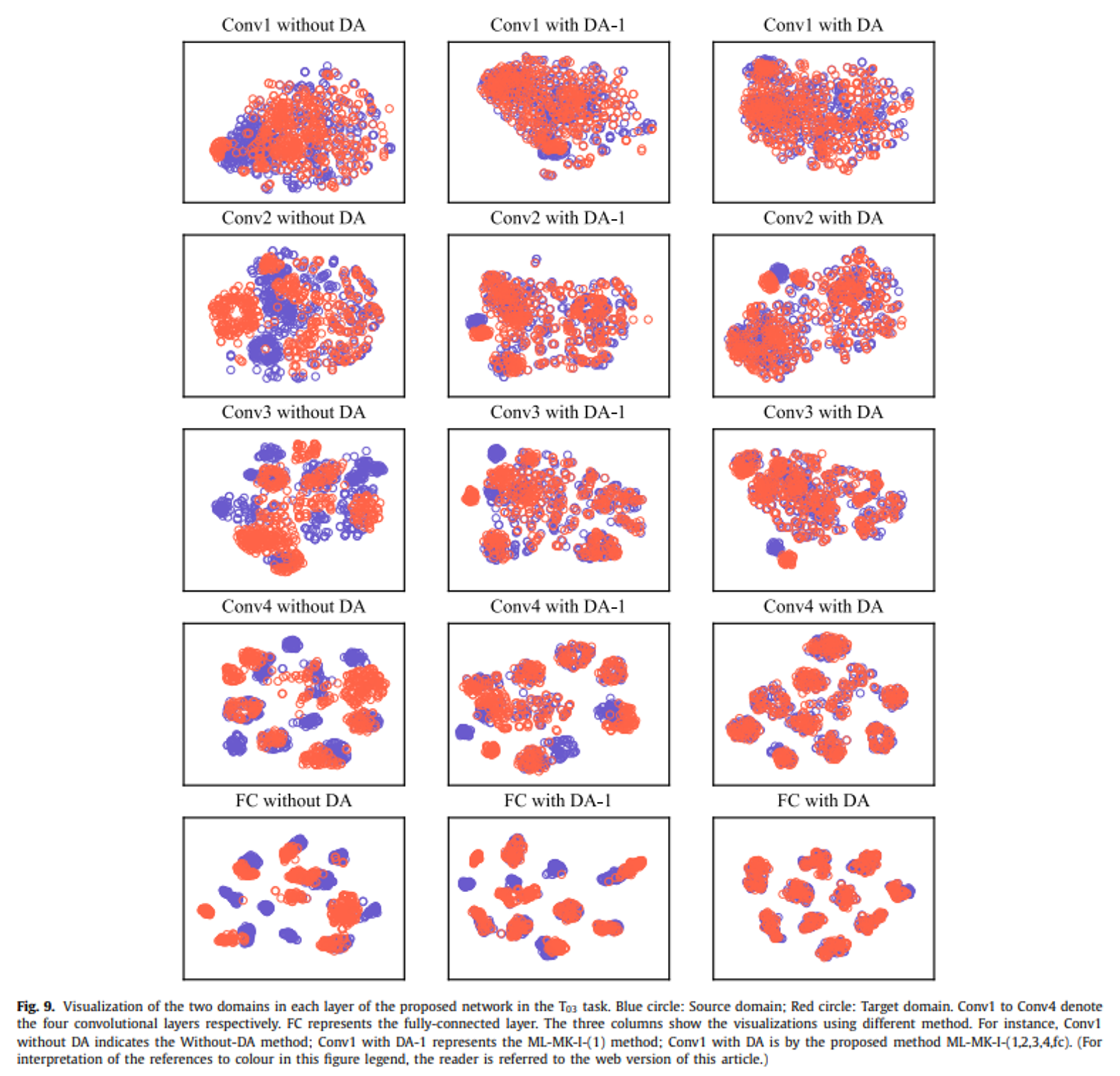
- 해석
- 모든 레이어에서 도메인간 분포차이 O
- but 상위 레이어에서 도메인 이동현상 두드러짐
- 하위 레이어가 일반적인 특징 추출, 상위레이어에서 고수준의 specific 특징 추출
4.3.4. Effects of parameters
4.3.5. Comparing with related works