0. Abstract
- Transformer 제안
- RNN, CNN모두 생략
- 오로지 어텐션 기반
- 병렬적으로 작동이 가능해서 학습 속도가 빨랐음
1. Introduction
- RNN기반 모델들은 그동안 대표적인 시퀀스 모델링, 시퀀스 변환모델
- 언어모델, 인코더-디코더 구조의 경계를 넓히려고 많이 노력했음
- 문제점) RNN기반 모델의 본질적인 순서 위치는 긴 시퀀스에서 치명적 (병렬적으로 작동X)
- 계산적 발전 이루었음에도 제약 여전히 발생
- 어텐션: input과 ouput시퀀스의 길이와 상관없이 다양한 task에서 시퀀스 모델링과 시퀀스 변환에서 짱됨
- 일부 RNN은 어텐션과 함께 쓰이기도 함
- Transformer제안: recurrent한 특징 제외하고, 어텐션 통해 입력과 출력 사이에 종속성 유지
- 병렬화 가능
- 짧은 학습 시간으로도 번역의 질 향상 가능
2. Background
- 시퀀스 계산 줄이는 방법: CNN방법 사용(Extended Neural GPU,ByteNet ,ConvS2S )
- 병렬적으로 모든 입력과 출력 위치들 계산
- 한계 존재) 필요 연산량이 위치간 거리에 따라 증가(=먼 위치 간의 의존성 학습 어렵게 만듦)
- Transformer에서 위 문제 해결
- 어텐션 가중치 평균화 → 유효한 해상도 줄임 (multi-head attention으로 해결)
- 순서 기반 RNN 안씀
- Self-attention
- 시퀀스의 서로 다른 위치 간의 관계 연관시켜서 시퀀스의 표현 계산
- 읽기 해석, 요약 등으로 성공적으로 쓰임
- Recurrent-attention
- End-to-end memory에서 사용, 순서대로의 recurrence X
- 간단한 질문에 대답 잘함
- =⇒ 그치만 Transformer가 얘보다 더 낫다.(순서 기반 RNN 안씀)
3. Model Architecture
- Transformer 특징
- 한번에 하나씩, 각 step은 자동 회귀적, 다음에 생성되는거는 이전꺼도 반영
- stack of self attention, point-wise, 인코더 디코더에 모두 fully connected layer
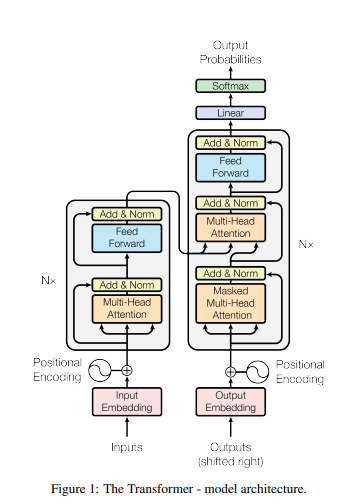
3-1. Encoder and Decoder Stacks
- 인코더 특징
- 6개의 identical layer
- 각 layer에는 2개의 sub layer
- 1번째: multi-head self attention
- 2번째: position wise fully connected feed forward network
- 각 layer에는 2개의 sub layer
- residual connection (2개의 sub layer 사이)
- sub layer결과(embedding layer포함) = layer norm, 512차원 출력
- layer norm
- 6개의 identical layer
- 디코더 특징
- 6개의 identical layer
- 각 layer에는 2개의 sub layer
- mask attention: 미래 정보 참조 못하게 하기 위해 mask씌움
- 각 layer에는 2개의 sub layer
- residual connection
- layer norm
- 6개의 identical layer
3-2. Attention
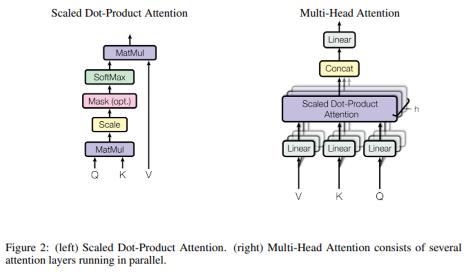
- 요소
- 쿼리, 키, 벨류
- output
- weighted sum of the values (유사성 함수를 통해 계산된 가중치)
3-2-1. Scaled Dot-Product Attention
- Scaled dot-product
- 그냥 dot product 하는 것 보다 scale 시 더 가벼워짐
- 유사도 값이 너무 크면 softmax가 saturate되고, gradient vanishing되기 때문
- dot-product
- scaled와 비슷, sqrt(D_Q) 만 뺌
- 더 빠르고, 공간 효율적일수있지만, 많은 연산 코드 필요
- additive attention
- 하나의 hidden layer가지고 feed forward network
- 더 작은 데이터에 유리
3-2-2. Multi-Head Attention
- single attention보다 multi attention이 더 성능 좋은걸 알아냄
- 병렬, 동시적으로 각 attention 계산
⇒ 동시적으로 각기 다른 subspace의 각기 다른 위치에서 계산
3-2-3. Applications of Attention in our Model
- 3가지 방법으로 우리 모델에서 attention 사용
- encoder-decoder attention: 쿼리: 이전 디코더 레이어로부터, key&value: 인코더의 output
- encoder의 self-attention: 키 쿼리 벨류 모두 인코더의 input으로 부터
- 디코더의 self-attention: 미래 정보 masking하기
3-3. Position-wise Feed-Forward Networks
- fully connected feed forward network
- 각 위치에 대해 분리되게 적용 가능
- 2개의 선형 변환이 있었기에 가능 (relu 활성화 함수사용)
3-4. Embeddings and Softmax
- 동일 W가중치를 임베딩 레이어마다, softmax이전에 사용
- 임베딩
- input token전환 & output token을 벡터로
- softmax
- 디코더의 output을 확률적으로 바꾸려고
3-5. Positional Encoding
- positional encoding
- embedding과 같은 차원 (이 두개가 더해질수있어야해서)
- 다양한 방
- 여기선 사인, 코사인 함수 사용
- 상대적인 위치에 따라 모델이 쉽게 학습할 수 있도록 하기 위해
- 어떤 고정된 오프셋 k에 대해서든 P Epos+k는 P Epos의 선형 함수로 표현될 수 있기 때문
- 더 긴 시퀀스 길이로 외삽(extrapolate)할 수 있을 것
- 여기선 사인, 코사인 함수 사용
4. Why Self-Attention
- 3가지 요구사항 기반으로 self attention 활용
- 레이어당 총 연산비용
- 동시성 있는 연산 (적은 연산으로)
- 장거리 의존성 간의 경로 길이
- 종속성을 학습하는 능력에 영향을 미치는 주요 요소 중 하나는 신호가 네트워크 내에서 이동해야 하는 경로의 길이
- 많은 시퀀스 변환 task에서 자주 요구되는 사항
- 다른 레이어 유형으로 구성된 네트워크에서 임의의 두 입력 및 출력 위치 간의 최대 경로 길이를 비교
5 Training
5-1. Training Data and Batching
데이터: standard WMT 2014 English-German dataset
5-2. Hardware and Schedule
5-3. Optimizer
Adam
5-4. Regularization
- Residual Dropout
- output of each sub-layer,
- ums of the embeddings and the positional encodings in both the encoder and decoder stacks
'2023 딥러닝 > 논문 리뷰' 카테고리의 다른 글
| [서베이 정리] Visual Anomaly Detection for Images: A Survey (2) | 2024.02.27 |
|---|